Generalized Linear Model (GLM)
PSYC 573
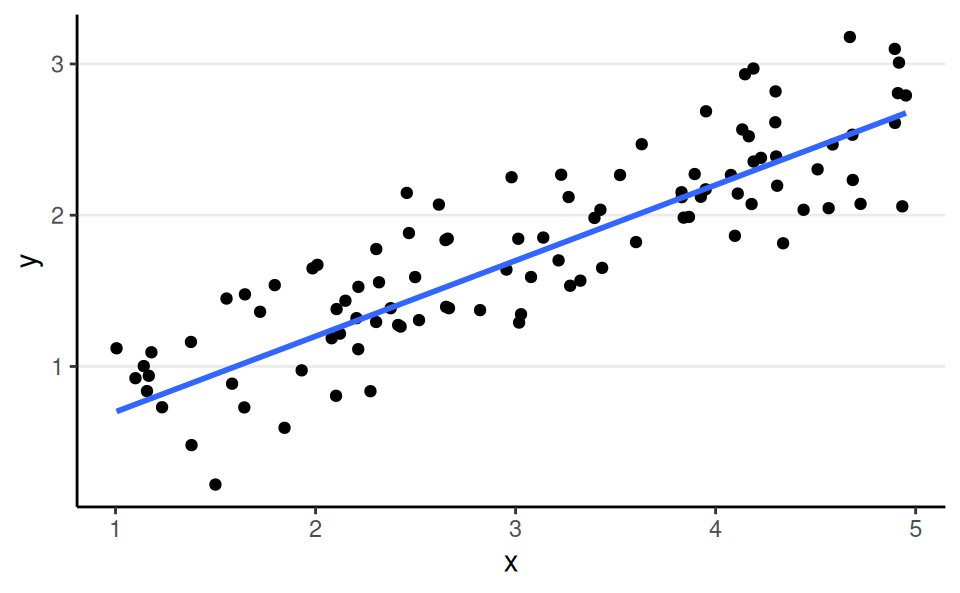
Normal, Identity Link
aka linear regression
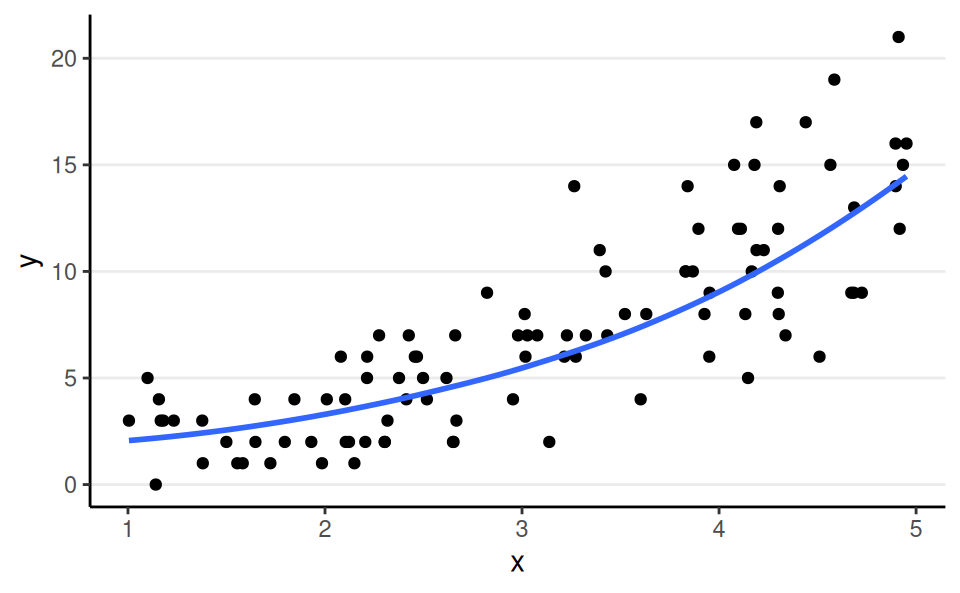
Poisson, Log Link
aka poisson regression
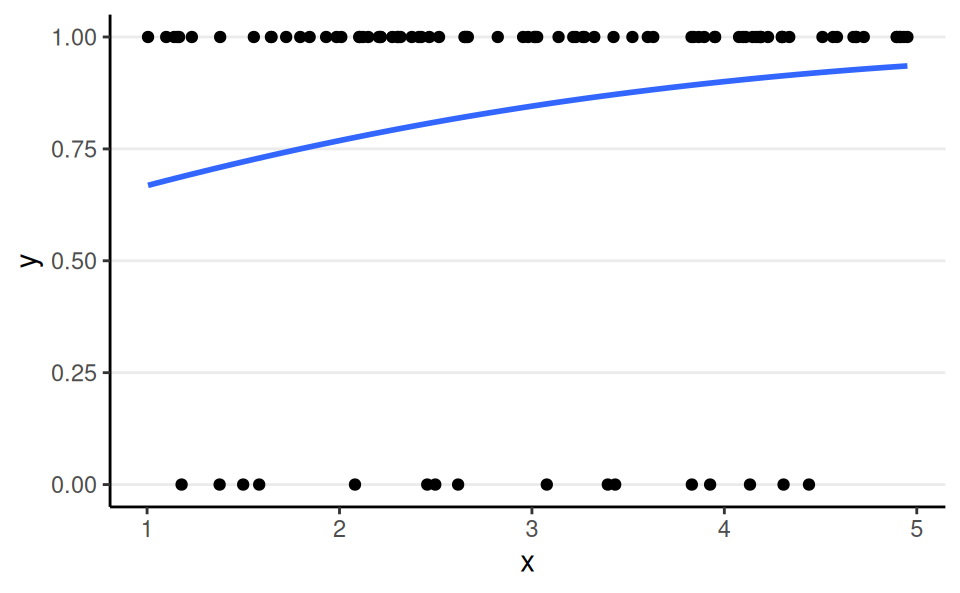
Bernoulli, Logit Link
aka binary logistic regression
Binomial, Logit Link
aka binomial logistic regression
\[ \begin{aligned} Y_i & \sim \mathrm{Bin}(N, \mu_i) \\ \log\left(\frac{\mu_i}{1 - \mu_i}\right) & = \eta_i \\ \eta_i & = \beta_0 + \beta_1 X_{i} \end{aligned} \]
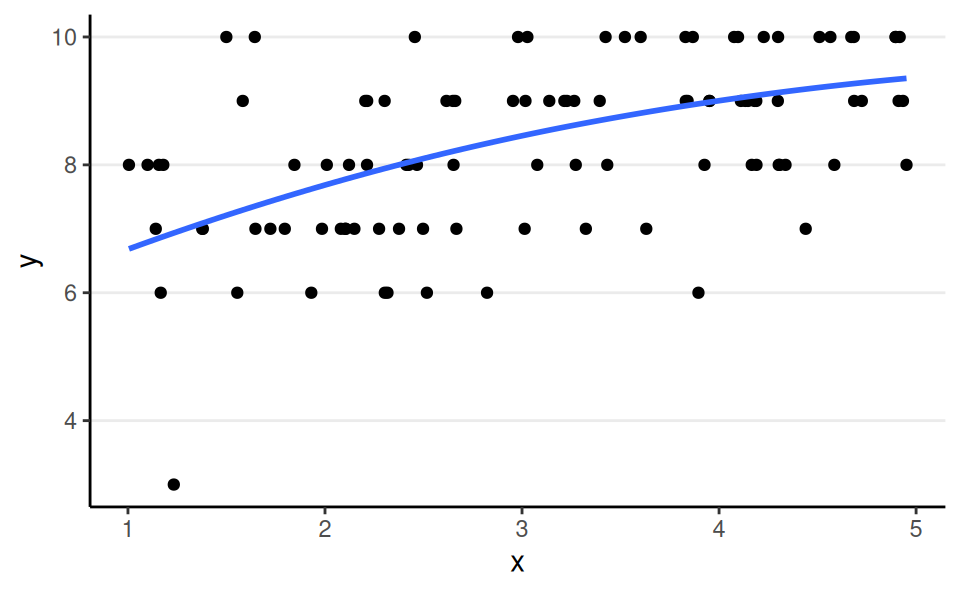
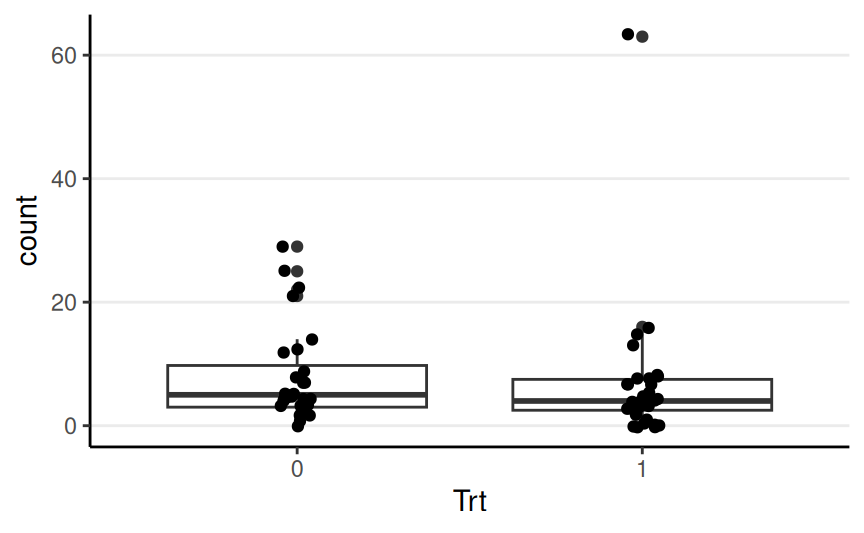
count: The seizure count between two visitsTrt: Either 0 or 1 indicating if the patient received anticonvulsant therapy
\[ \begin{aligned} \text{count}_i & \sim \mathrm{Pois}(\mu_i) \\ \log(\mu_i) & = \eta_i \\ \eta_i & = \beta_0 + \beta_1 \text{Trt}_{i} \end{aligned} \]