How to Choose \(\kappa\)
If \(\kappa \to \infty\): everyone is the same; no individual differences (i.e., complete pooling)
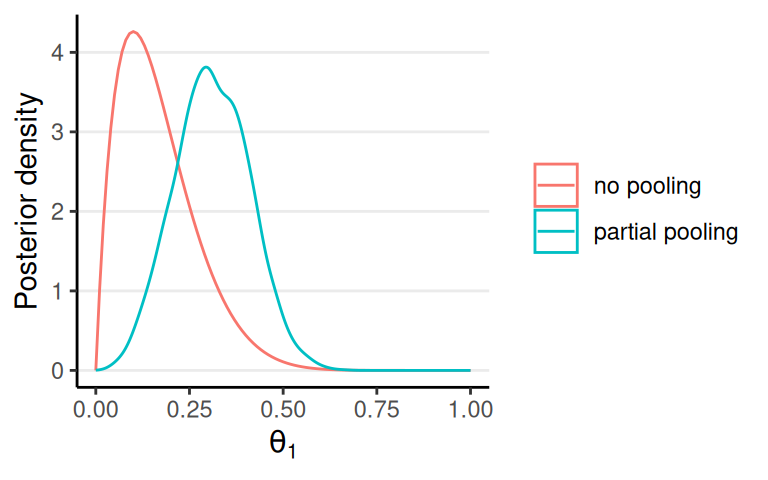
If \(\kappa = 0\): everybody is different; nothing is shared (i.e., no pooling)
We can fix a \(\kappa\) value based on our belief of how individuals are similar or different
A more Bayesian approach is to treat \(\kappa\) as an unknown, and use Bayesian inference to update our belief about \(\kappa\)
Full Model
Model: \[
\begin{aligned}
z_j & \sim \mathrm{Bin}(N_j, \theta_j) \\
\theta_j & \sim \mathrm{Beta2}(\mu, \kappa)
\end{aligned}
\] Prior: \[
\begin{aligned}
\mu & \sim \mathrm{Beta}(1.5, 1.5) \\
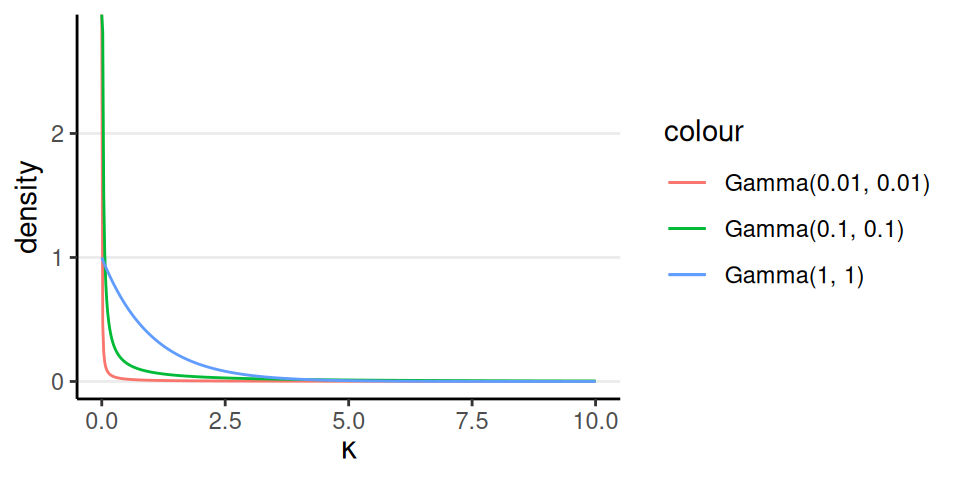
\kappa & \sim \mathrm{Gamma}(0.01, 0.01)
\end{aligned}
\]
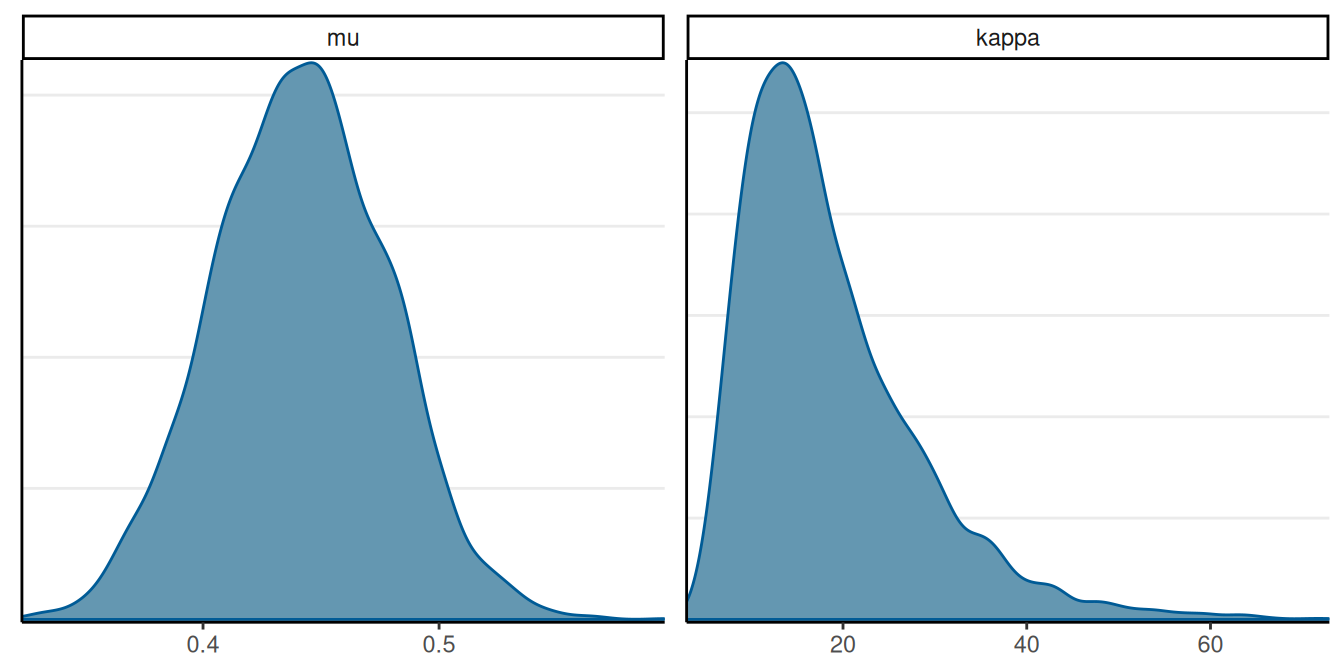
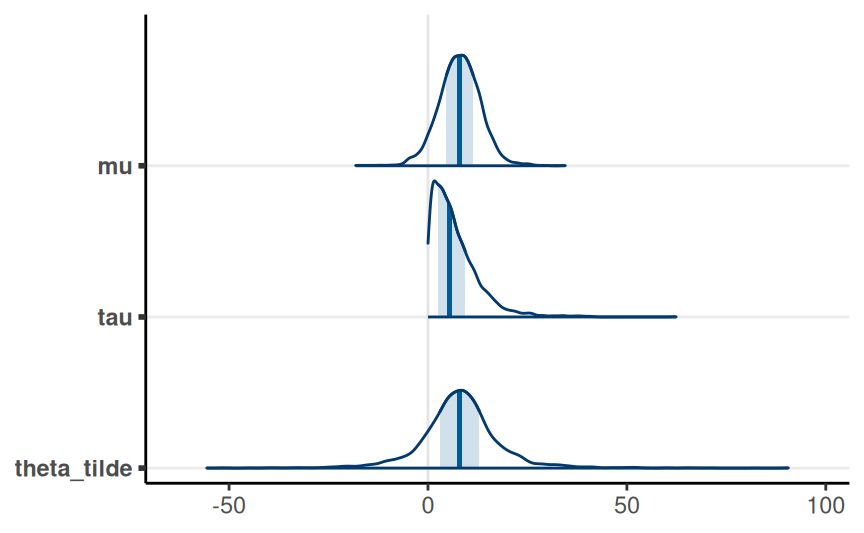
Posterior of Hyperparameters
library(bayesplot)
tt_fit$draws(c("mu", "kappa")) |>
mcmc_dens()
![]()
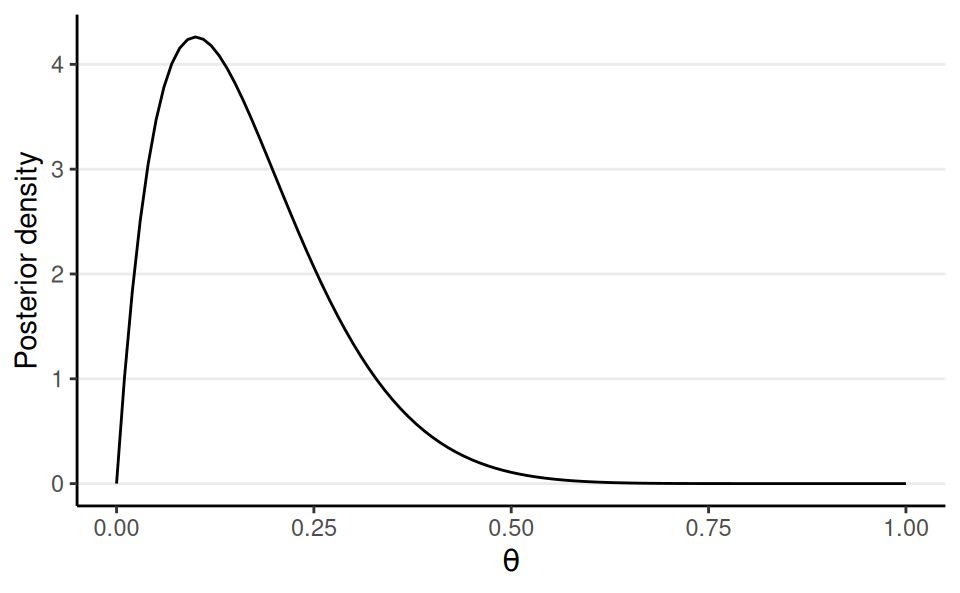
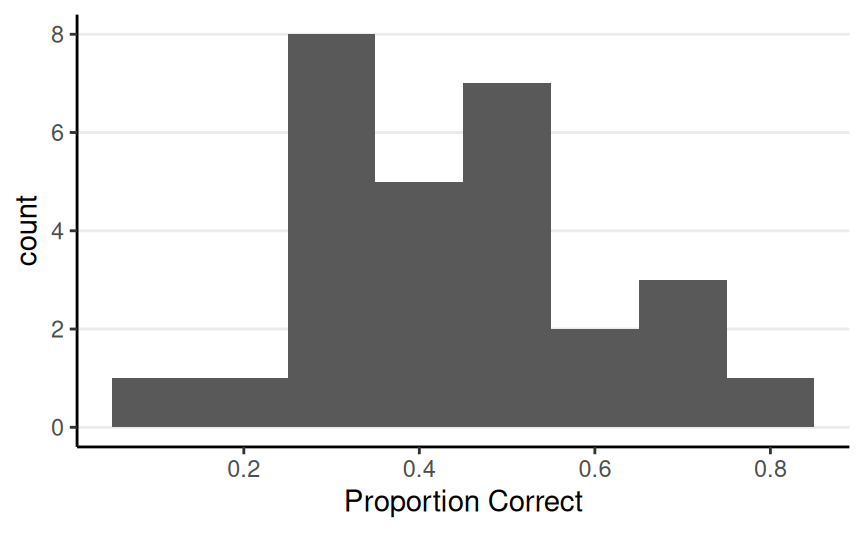
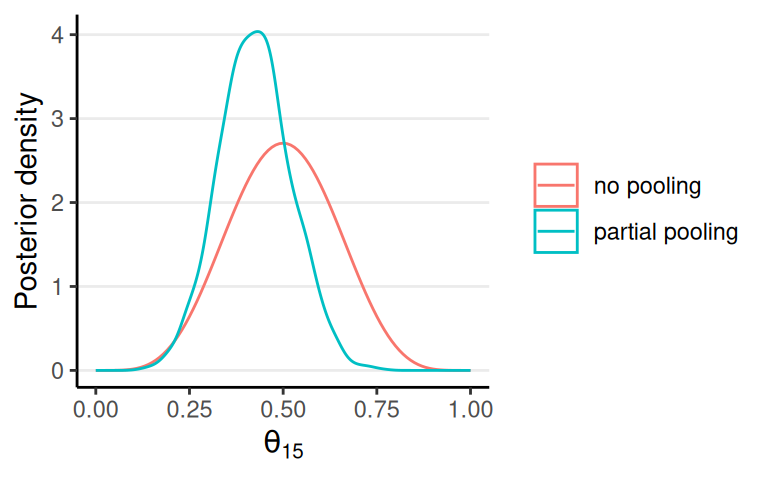
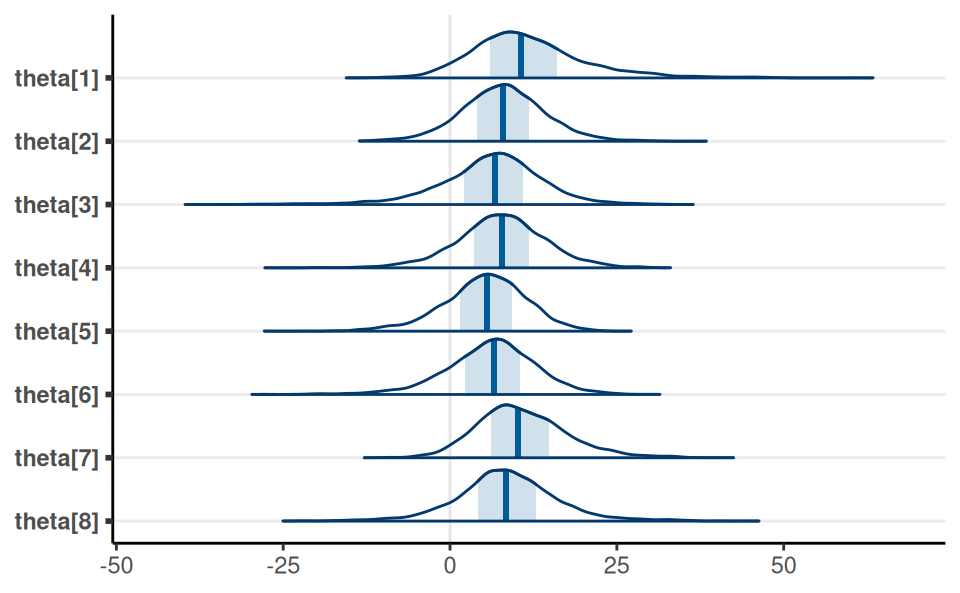
Shrinkage