| Trial | Outcome |
|---|---|
| 1 | 2 |
| 2 | 3 |
| 3 | 1 |
| 4 | 3 |
| 5 | 1 |
| 6 | 1 |
| 7 | 5 |
| 8 | 6 |
| 9 | 3 |
| 10 | 3 |
Probability and Bayes Theorem
PSYC 573
2024-09-03
History of Probability
Origin: To study gambling problems
A mathematical way to study uncertainty/randomness
Thought Experiment
Someone asks you to play a game. The person will flip a coin. You win $10 if it shows head, and lose $10 if it shows tail. Would you play?

Throwing a Die With Six Faces

\(A_1\) = getting a one, . . . \(A_6\) = getting a six
- \(P(A_i) \geq 0\)
- \(P(\text{the number is 1, 2, 3, 4, 5, or 6}) = 1\)
- \(P(\text{the number is 1 or 2}) = P(A_1) + P(A_2)\)
Mutually exclusive: \(A_1\) and \(A_2\) cannot both be true
Classical Interpretation

- Number of target outcomes / Number of possible “indifferent” outcomes
- E.g., Probability of getting “1” when throwing a die: 1 / 6
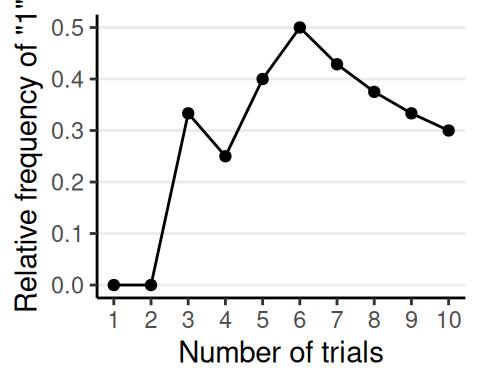
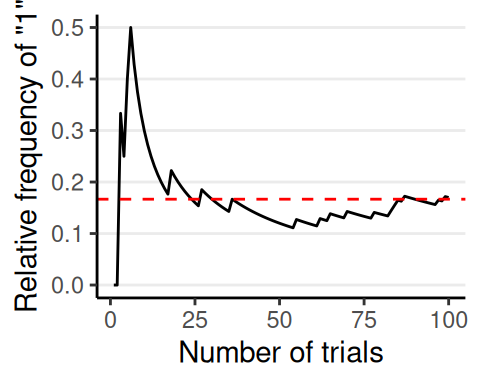
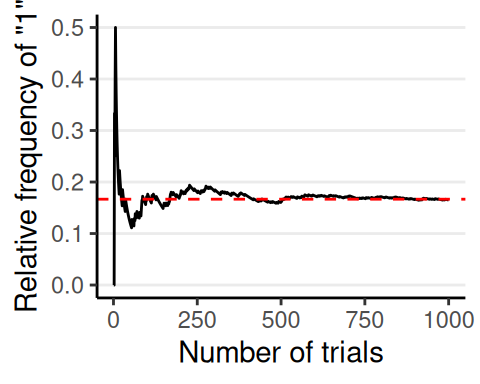
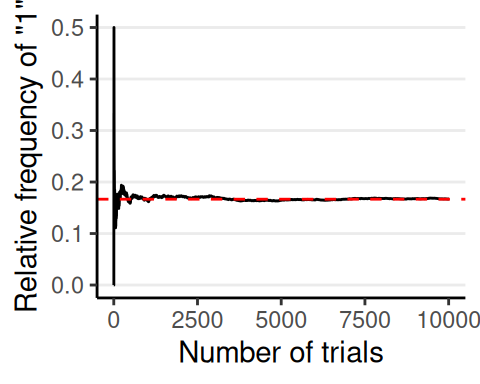
Frequentist Interpretation
- Long-run relative frequency of an outcome
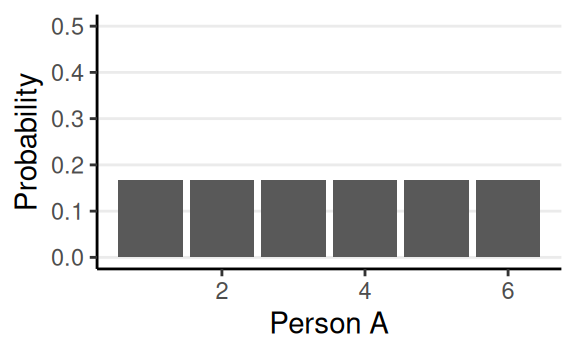
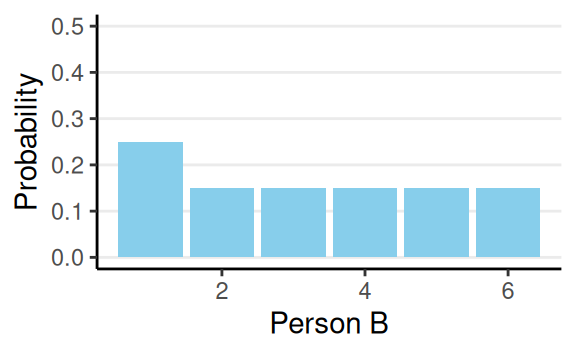
Subjectivist Interpretation
- State of one’s mind; the belief of all outcomes
- Subjected to the constraints of:
- Axioms of probability
- That the person possessing the belief is rational
- Subjected to the constraints of:
Probability Distributions
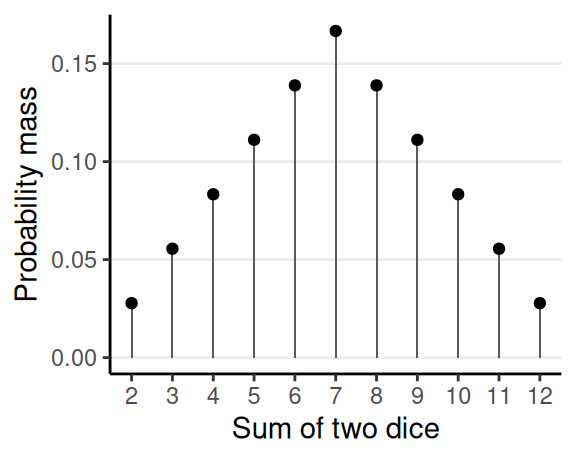
Discrete outcome: Probability mass
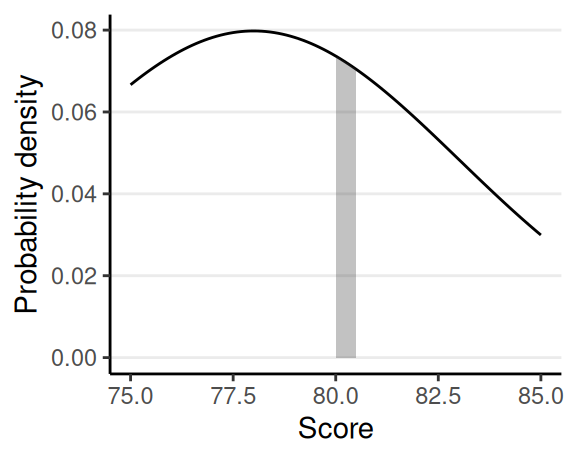
Continuous outcome: Probability density
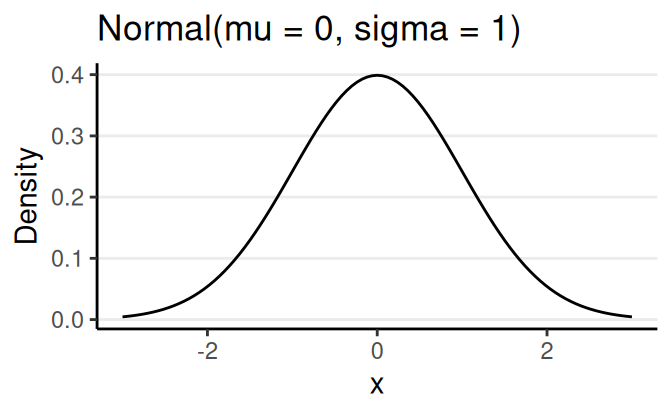
Normal Probability Density
Some Commonly Used Distributions

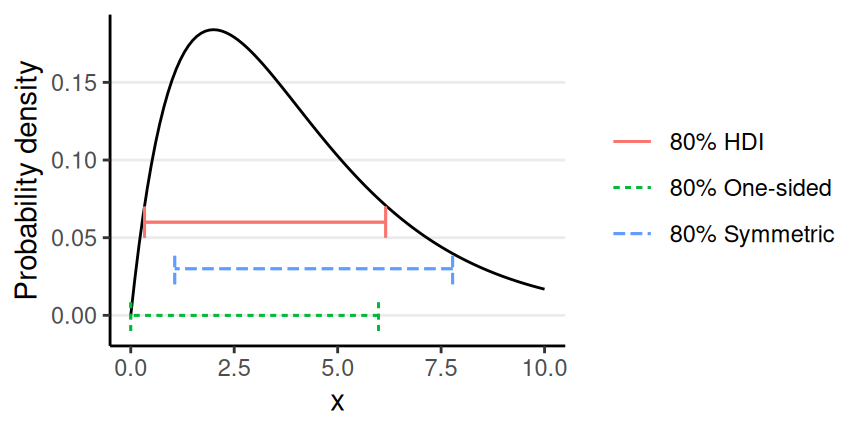
Summarizing a Probability Distribution (cont’d)
Multiple Variables
- Joint probability: \(P(X, Y)\)
- Marginal probability: \(P(X)\), \(P(Y)\)
| >= 4 | <= 3 | Marginal (odd/even) | |
|---|---|---|---|
| odd | 1/6 | 2/6 | 3/6 |
| even | 2/6 | 1/6 | 3/6 |
| Marginal (>= 4 or <= 3) | 3/6 | 3/6 | 1 |
Multiple Continuous Variables
- Left: Continuous \(X\), Discrete \(Y\)
- Right: Continuous \(X\) and \(Y\)
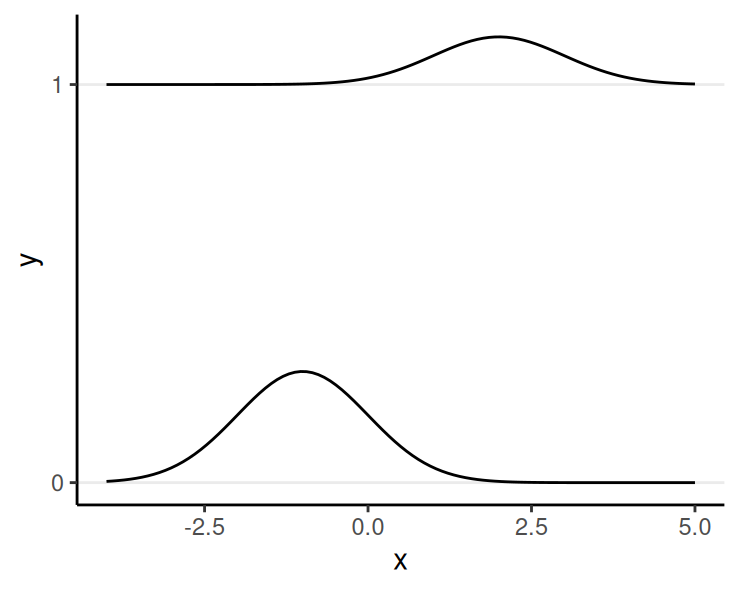
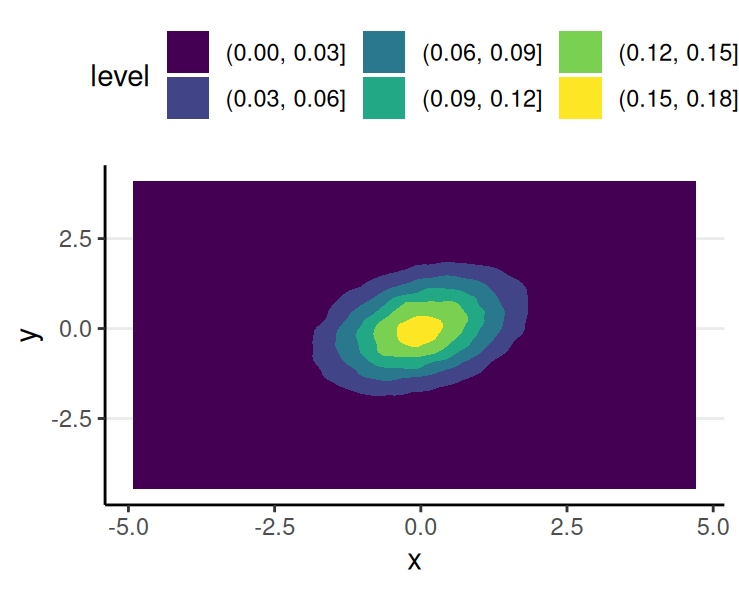
Law of Total Probability
From conditional \(P(A \mid B)\) to marginal \(P(A)\)
- If \(B_1, B_2, \cdots, B_n\) are all possibilities for an event (so they add up to a probability of 1), then
\[ \begin{align} P(A) & = P(A, B_1) + P(A, B_2) + \cdots + P(A, B_n) \\ & = P(A \mid B_1)P(B_1) + P(A \mid B_2)P(B_2) + \cdots + P(A \mid B_n) P(B_n) \\ & = \sum_{k = 1}^n P(A \mid B_k) P(B_k) \end{align} \]
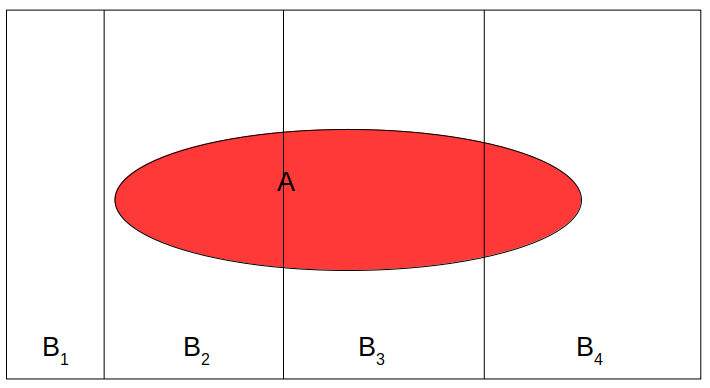
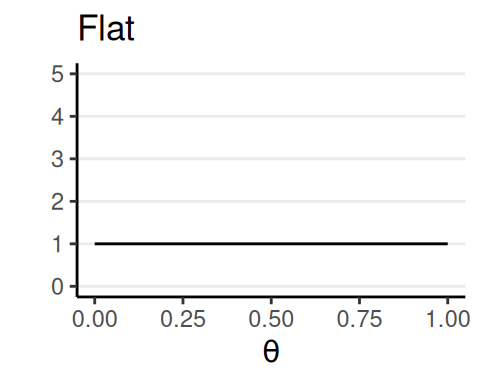
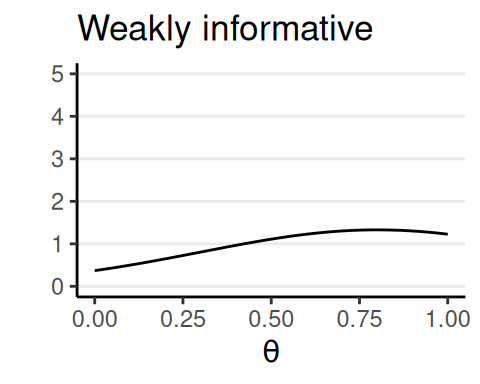
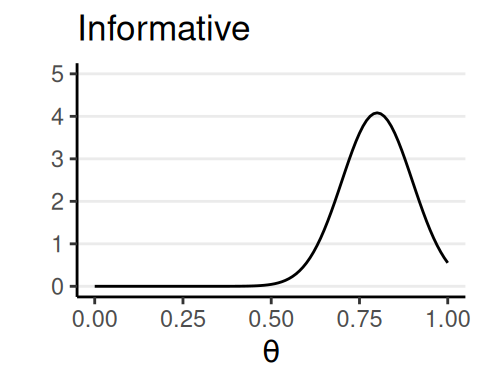
Priors
Prior beliefs used in data analysis must be admissible by a skeptical scientific audience (Kruschke, 2015, p. 115)
- Flat, noninformative, vague
- Weakly informative: common sense, logic
- Informative: publicly agreed facts or theories
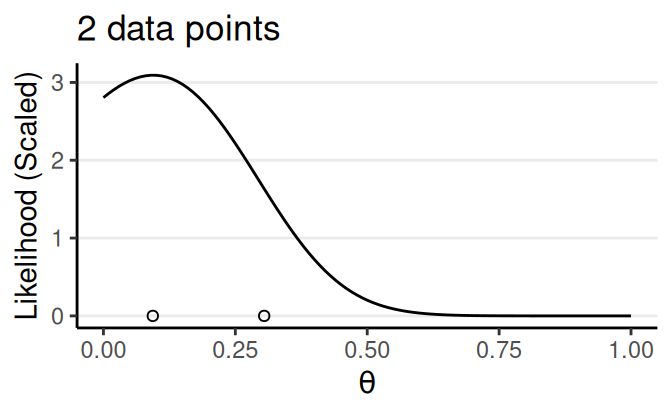
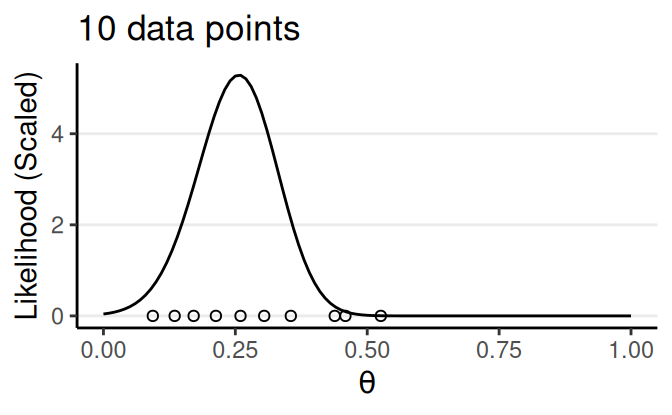
Likelihood/Model/Data \(P(D \mid \theta, M)\)
Probability of observing the data as a function of the parameter(s)
- Also written as \(L(\theta \mid D)\) or \(L(\theta; D)\) to emphasize it is a function of \(\theta\)
- Also depends on a chosen model \(M\): \(P(D \mid \theta, M)\)
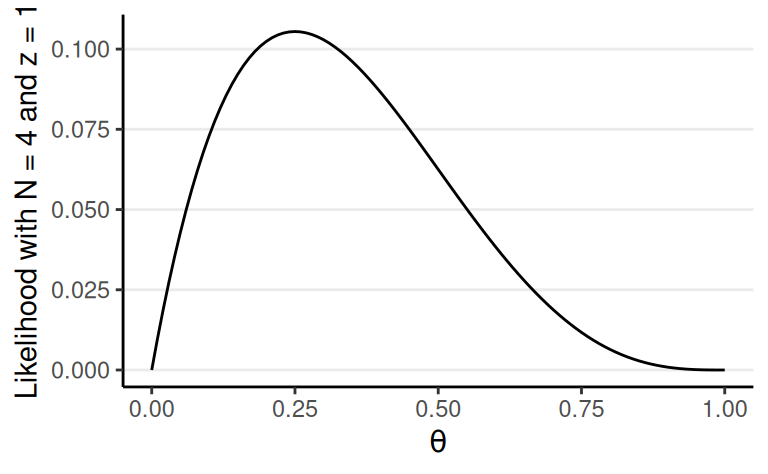
Multiple Binary Outcomes
Bernoulli model is natural for binary outcomes
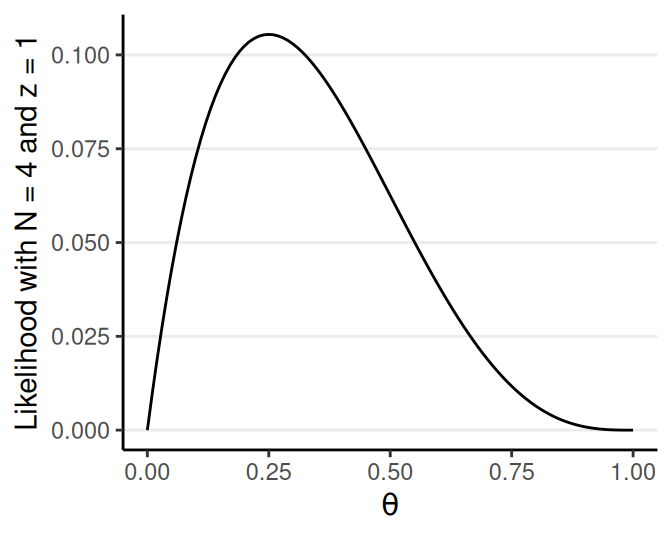
Assume the flips are exchangeable given \(\theta\), \[ \begin{align} P(y_1, \ldots, y_N \mid \theta) &= \prod_{i = 1}^N P(y_i \mid \theta) \\ &= \theta^z (1 - \theta)^{N - z} \end{align} \]
\(z\) = # of heads; \(N\) = # of flips
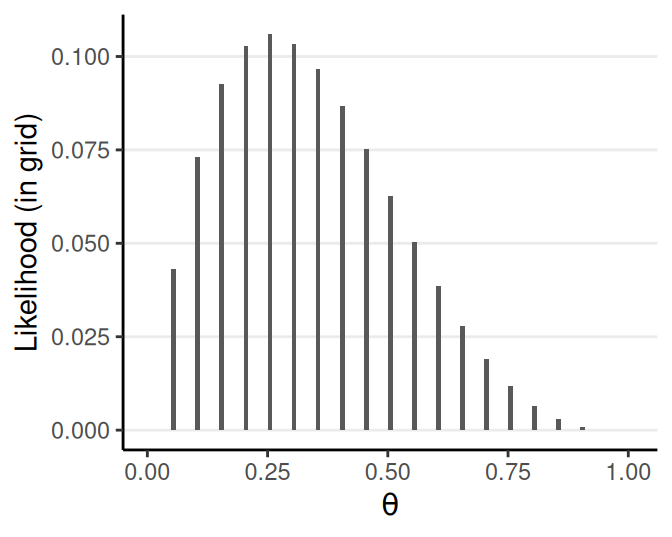
Grid Approximation
See Exercise 2
Discretize a continuous parameter into a finite number of discrete values
For example, with \(\theta\): [0, 1] \(\to\) [.05, .15, .25, …, .95]