flowchart LR
subgraph DATA
direction TB
A[Identify/Collect Data] --> B[Visualize Data]
end
%% B --> C[Choose/Modify Model]
subgraph MODEL
H -->|Model fit not satisfactory|C
C[Choose/Modify Model] --> D[Specify Priors]
D --> E[Prior Predictive Check]
E --> G[MCMC Sampling with Convergence diagnostics]
G --> H[Posterior Predictive Check]
end
subgraph RESULTS
%% I -->|Model is reasonable|J[Model comparisons/averaging]
J[Model comparisons/averaging] --> K[Interpret and Visualize Results]
end
DATA --> MODEL
MODEL --> RESULTS
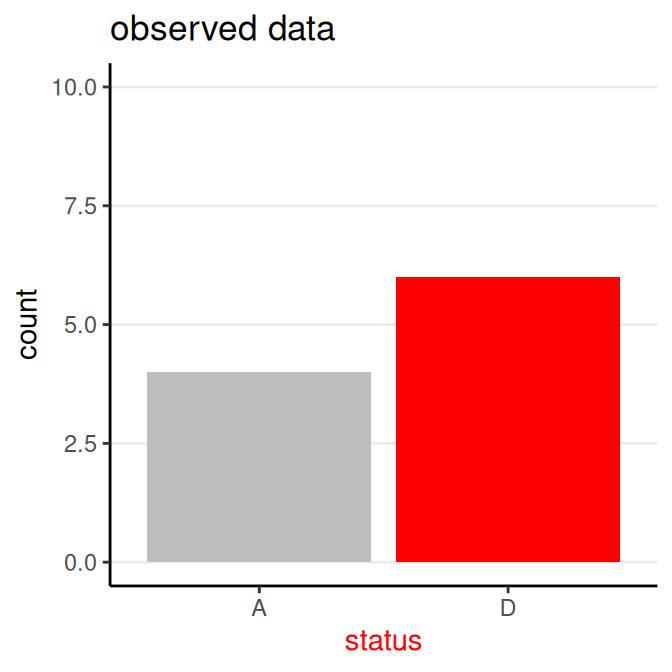
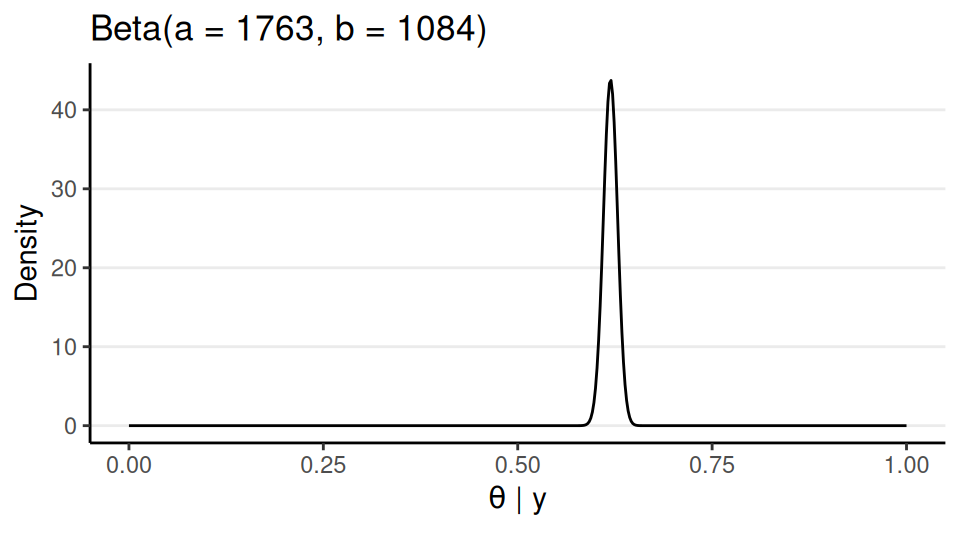
Choose a Model: Bernoulli
Data: \(y\) = survival status (0 = “A”, 1 = “D”)
Parameter: \(\theta\) = probability of “D”
Model equation: \(y_i \sim \text{Bern}(\theta)\) for \(i = 1, 2, \ldots, N\)
The model states:
the sample data \(y\) follows a Bernoulli distribution with the common parameter \(\theta\)
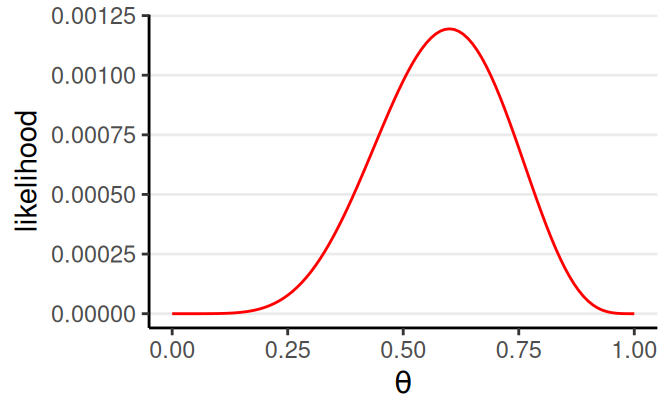
Bernoulli Likelihood
Notice that there is no subscript for \(\theta\):
The model assumes each observation has the same \(\theta\)
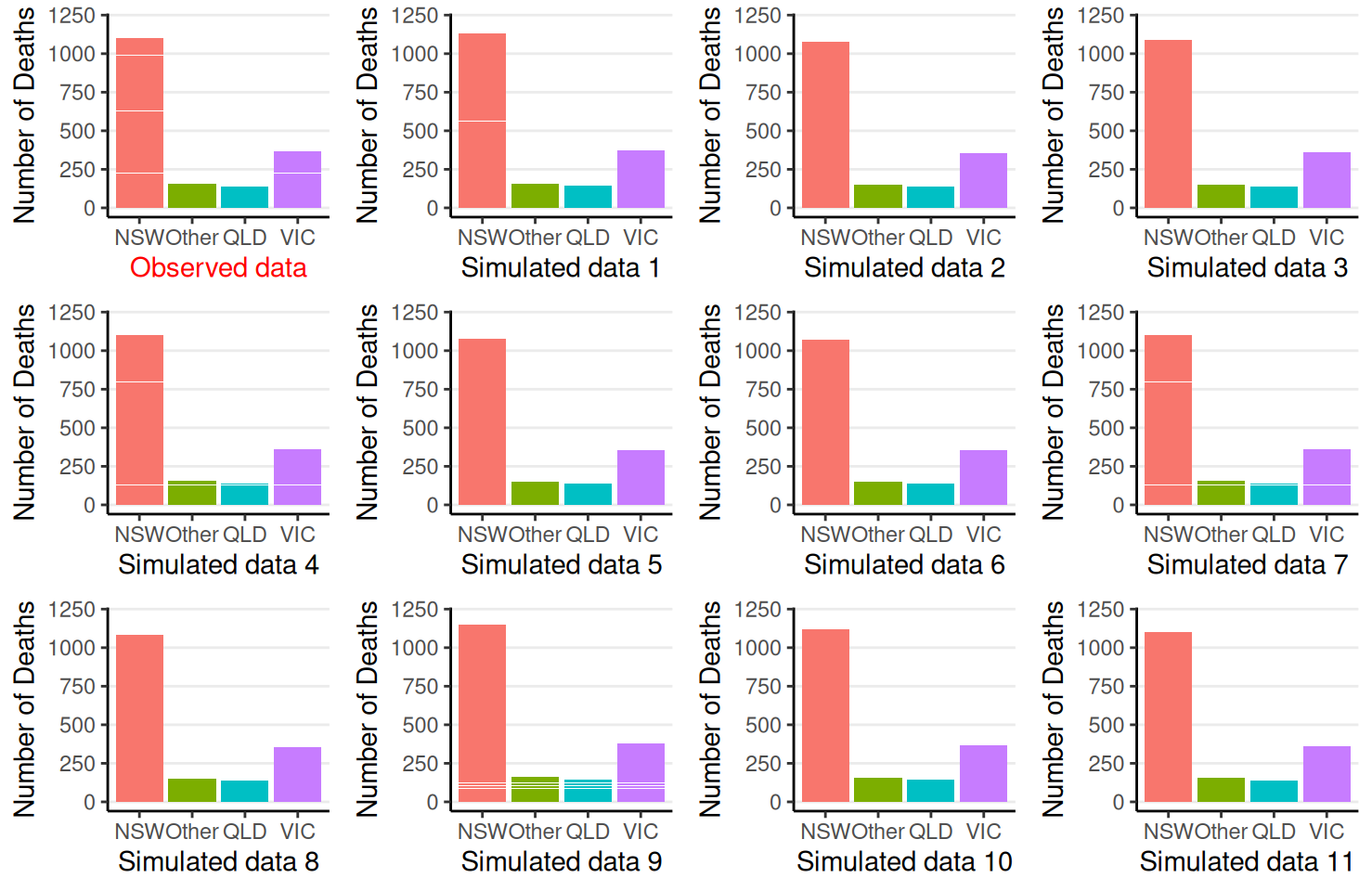
Here we use the function bayesplot::ppc_stat_grouped()
1age50 <-factor(Aids2$age >50, labels =c("<= 50", "> 50"))2bern_pp_fit$draws("ytilde", format ="draws_matrix") |>3ppc_stat_grouped(y = Aids2_standata$y, group = age50, stat ="mean")
1
Create binary indicator of two age groups
2
Extract simulated data sets
3
Plot a histogram of the sample means from the simulated data (i.e., posterior predictive distribution) for each age group
Other One-Parameter Models
Binomial Model
For count outcome: \(y_i \sim \mathrm{Bin}(N_i, \theta)\)
\(\theta\): rate of occurrence (per trial)
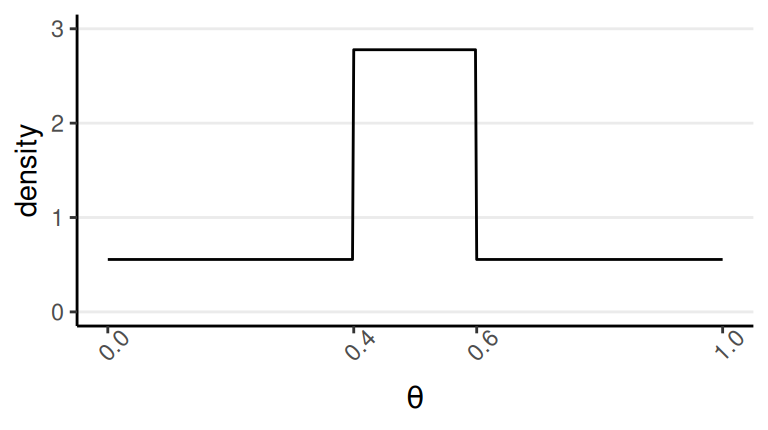
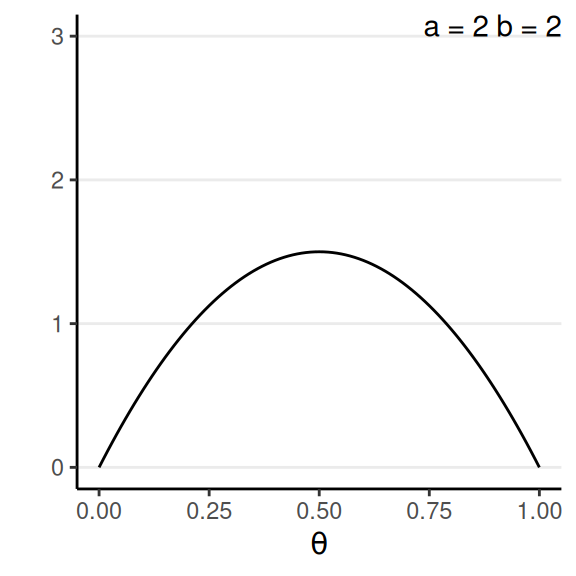
Conjugate prior: Beta
E.g.,
\(y\) minority candidates in \(N\) new hires
\(y\) out of \(N\) symptoms checked
A word appears \(y\) times in a tweet of \(N\) number of words
Poisson Model
For count outcome: \(y_i \sim \mathrm{Pois}(\theta)\)
\(\theta\): rate of occurrence
Conjugate prior: Gamma
E.g.,
Drinking \(y\) times in a week
\(y\) hate crimes in a year for a county
\(y\) people visiting a store in an hour
Bibliography
Gabry, Jonah, Daniel Simpson, Aki Vehtari, Michael Betancourt, and Andrew Gelman. 2019. “Visualization in Bayesian Workflow.”Journal of the Royal Statistical Society Series A: Statistics in Society 182 (2): 389–402. https://doi.org/10.1111/rssa.12378.
Gelman, Andrew, Aki Vehtari, Daniel Simpson, Charles C. Margossian, Bob Carpenter, Yuling Yao, Lauren Kennedy, Jonah Gabry, Paul-Christian Bürkner, and Martin Modrák. 2020. “Bayesian Workflow.” arXiv. https://doi.org/10.48550/ARXIV.2011.01808.