In statistical modeling, a more complex model almost always results in a better fit to the data. Roughly speaking, a more complex model means a model with more parameters. However, as you will see later, determining the number of parameters in Bayesian analyses is not straightforward. On the extreme side, if one has 10 observations, a model with 10 parameters will perfectly predict every single data point (by just having a parameter to predict each data point). However, there are two problems with too complex a model. First, an increasingly complex model makes it increasingly hard to extract useful information from the data. Instead of describing the relationship between two variables, like Marriage and Divorce, by a straight line, one ends up with a crazy model that is difficult to make sense of. Second, as you will also see, the more complex a model, the more is the risk that it overfits the current data, such that it does not work for future observations.
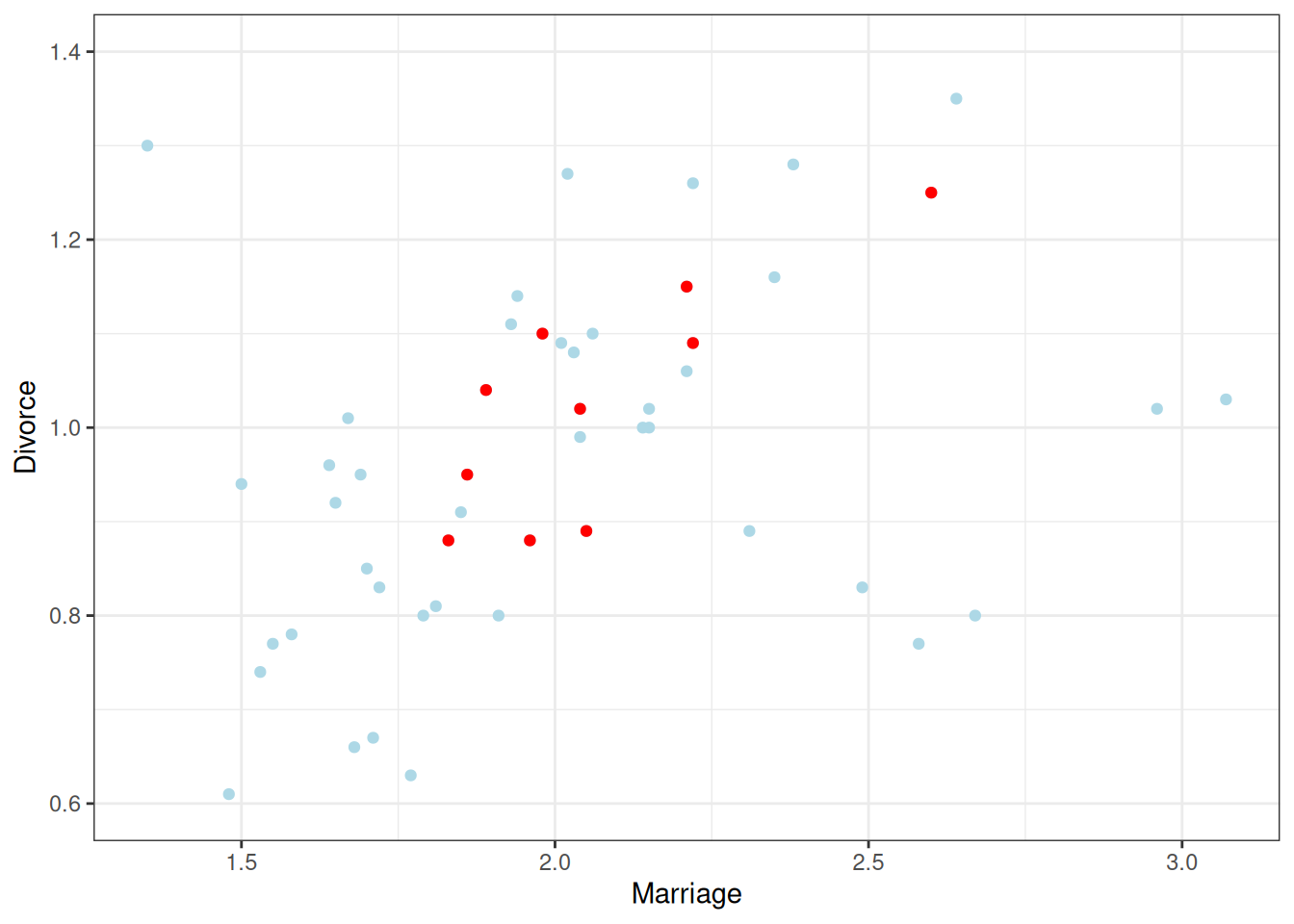
For example, let’s randomly sample 10 states in the waffle_divorce data set and build some models.
Rows: 50 Columns: 13
── Column specification ────────────────────────────────────────────────────────
Delimiter: ";"
chr (2): Location, Loc
dbl (11): Population, MedianAgeMarriage, Marriage, Marriage SE, Divorce, Div...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
# Rescale Marriage and Divorce by dividing by 10waffle_divorce$Marriage<-waffle_divorce$Marriage/10waffle_divorce$Divorce<-waffle_divorce$Divorce/10waffle_divorce$MedianAgeMarriage<-waffle_divorce$MedianAgeMarriage/10# Recode `South` to a factor variablewaffle_divorce$South<-factor(waffle_divorce$South, levels =c(0, 1), labels =c("non-south", "south"))
set.seed(1547)# set the seed for reproducibility# Sample 10 observationstrain<-sample.int(nrow(waffle_divorce), 10L)wd_sub<-waffle_divorce[train, ]base<-ggplot(aes(x =Marriage, y =Divorce), data =wd_sub)+geom_point()+coord_cartesian(ylim =c(0.6, 1.4))+xlim(range(waffle_divorce$Marriage))ggplot(waffle_divorce,aes(x =Marriage, y =Divorce))+geom_point(col ="lightblue")+geom_point(size =1.5, data =wd_sub, col ="red")+coord_cartesian(ylim =c(0.6, 1.4))+xlim(range(waffle_divorce$Marriage))
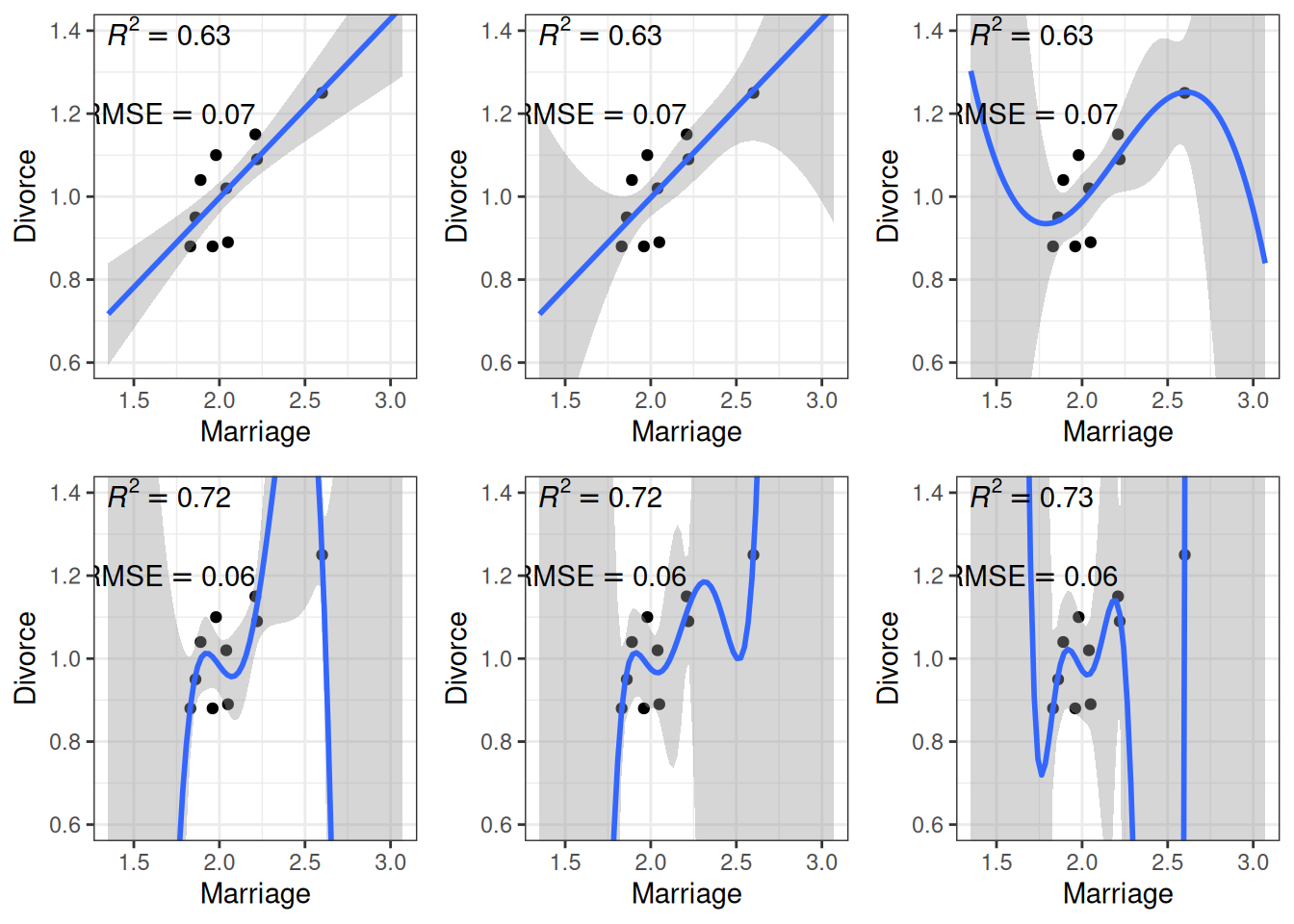
When using Marriage to predict Divorce, we can use beyond a linear regression line by using higher-order polynomials. For example, a second-order polynomial represents a quadratic effect (with one turning point); it goes to cubic, quartic, and more. The figure below shows the fit from a linear effect of Marriage, a quadratic effect, and increasingly complex models up to a sixth-degree polynomial. As you can see, as the model gets more complex, the fitted line tries to capture all the 10 points really well, with an increasing \(R^2\). However, the standard error around the fitted line also gets larger and bizarre, meaning more uncertainty in the model parameters.
Code
r2<-function(object, newresp, newdata){# Function for computing R^2ypred<-predict(object, newdata =newdata)cor(ypred, newresp)^2}rmse<-function(object, newresp, newdata){# Function for RMSEypred<-predict(object, newdata =newdata)sqrt(mean((ypred-newresp)^2))}# Create six plots through a loopp_list<-map(1:6, function(i){# Use frequentist analyses for speedmod<-lm(Divorce~poly(Marriage, degree =i), data =wd_sub)base+geom_smooth(method ="lm", formula =y~poly(x, i), level =.80, fullrange =TRUE)+annotate("text", x =1.7, y =1.4, label =paste0("italic(R)^2 == ",round(r2(mod, wd_sub$Divorce), 2)), parse =TRUE)+annotate("text", x =1.7, y =1.2, label =paste0("RMSE == ",round(rmse(mod, wd_sub$Divorce), 2)), parse =TRUE)})do.call(grid.arrange, c(p_list, nrow =2))
Figure 11.1: Fit of models on the 10 random cases. Top panel: linear, quadratic, and cubic; bottom panel: 4th, 5th, and 6th degree polynomials
Another way to look at model accuracy is the Root Mean Squared Error (RMSE), defined as the square root of the average squared prediction error. RMSE is a measure of prediction error. The smaller the RMSE, the better the prediction is. As you can see in the above figure, more complex models always reduce the RMSE in the data we use to fit the model (also called training data).
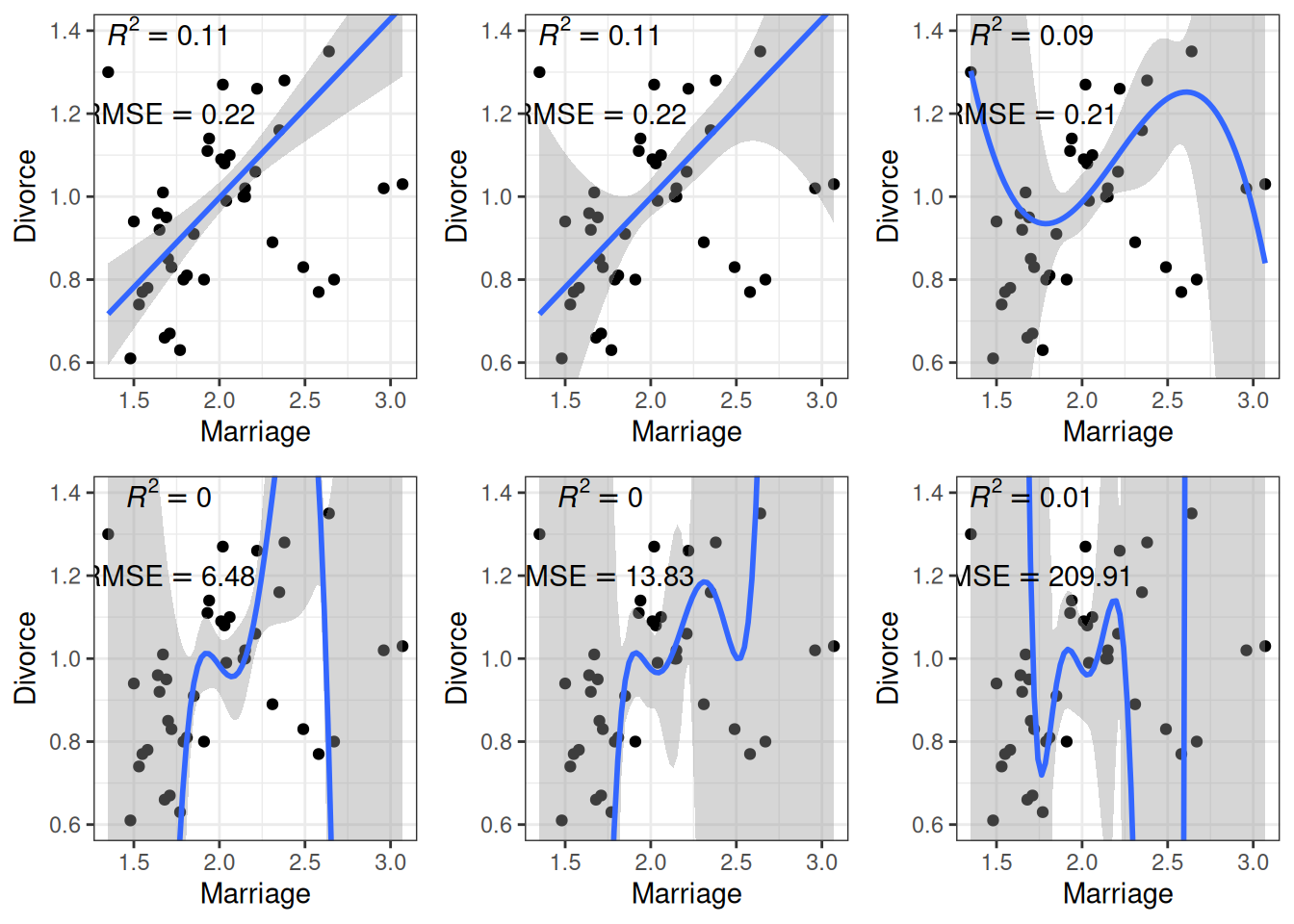
However, if I take the estimated regression line/curve based on the subsample of 10 observations, and predict the remaining cases in the data set, things will be different. As you can see in the figure below, whereas prediction error is comparable for the linear and the quadratic model, polynomials of higher degrees predict the data really badly. When you use a complex model in a data set, it tailors the coefficients to any sampling errors and noise in the data such that it will not generalize to new observations. Therefore, our goal in model comparison is to choose a model complex enough to capture the essence of the data generation process (and thus avoid underfitting), but not too complex such that it suffers from overfitting.
Code
base2<-ggplot(aes(x =Marriage, y =Divorce), data =waffle_divorce[-train, ])+geom_point()+coord_cartesian(ylim =c(0.6, 1.4))+xlim(range(waffle_divorce$Marriage))# Create six plots through a loopp_list2<-map(1:6, function(i){# Use frequentist analyses for speedmod<-lm(Divorce~poly(Marriage, degree =i), data =wd_sub)# New data and responsetest_dat<-waffle_divorce[-train, ]ynew<-test_dat$Divorcebase2+geom_smooth(data =wd_sub, method ="lm", formula =y~poly(x, i), level =.80, fullrange =TRUE)+annotate("text", x =1.7, y =1.4, label =paste0("italic(R)^2 == ",round(r2(mod, ynew, test_dat), 2)), parse =TRUE)+annotate("text", x =1.7, y =1.2, label =paste0("RMSE == ",round(rmse(mod, ynew, test_dat), 2)), parse =TRUE)})do.call(grid.arrange, c(p_list2, nrow =2))
Figure 11.2: Using the regression lines based on 10 random cases to predict the remaining 40 cases. Top panel: linear, quadratic, and cubic; bottom panel: 4th, 5th, and 6th degree polynomials
The goal of statistical modeling is to choose an optimal model between the overfitting/underfitting dichotomy. In machine learning, this is also commonly referred to as the bias-variance trade-off, as a model that is too simple tends to produce biased predictions because it does not capture the essence of the data generating process. In contrast, a overly complex model is unbiased but results in a lot of uncertainty in the prediction because there are too many unnecessary components that can affect predictions, as indicated in the confidence bands around the 6th-degree polynomial line.
Polynomials of varying degrees are merely one example of comparing simple to complex models. You can think about:
models with and without interactions,
models with a few predictors versus hundreds of predictors,
regression analyses versus multilevel models, etc.
Whereas one can always avoid underfitting by fitting a more and more complex model, we need tools to keep us from overfitting. This lecture is about finding an optimal model that avoids overfitting and avoids underfitting. You will learn to perform model comparisons with information criteria to find a model that has a better balance between overfitting and underfitting.
11.2 Kullback-Leibler Divergence
When comparing models (e.g., linear vs. quadratic), we prefer models closer to the “true” data-generating process. To do so, we need some ways to quantify the degree of “closeness” to the true model. In this context, models comprise both the distributional family and the parameter values. For example, the model \(y_i \sim N(5, 2)\) is a different model than \(y_i \sim N(3, 2)\), which is a different model than \(y_i \sim \mathrm{Gamma}(2, 2)\). The first two have the same family but different parameter values (different means, same \(\mathit{SD}\)). In contrast, the last two have different distributional families (Normal vs. Gamma).
To measure the degree of “closeness” between two models, \(M_0\) and \(M_1\), by far the most popular metric in statistics is the Kullback-Liebler Divergence (or Kullback-Liebler discrepancy; \(D_\textrm{KL}\)). By definition,
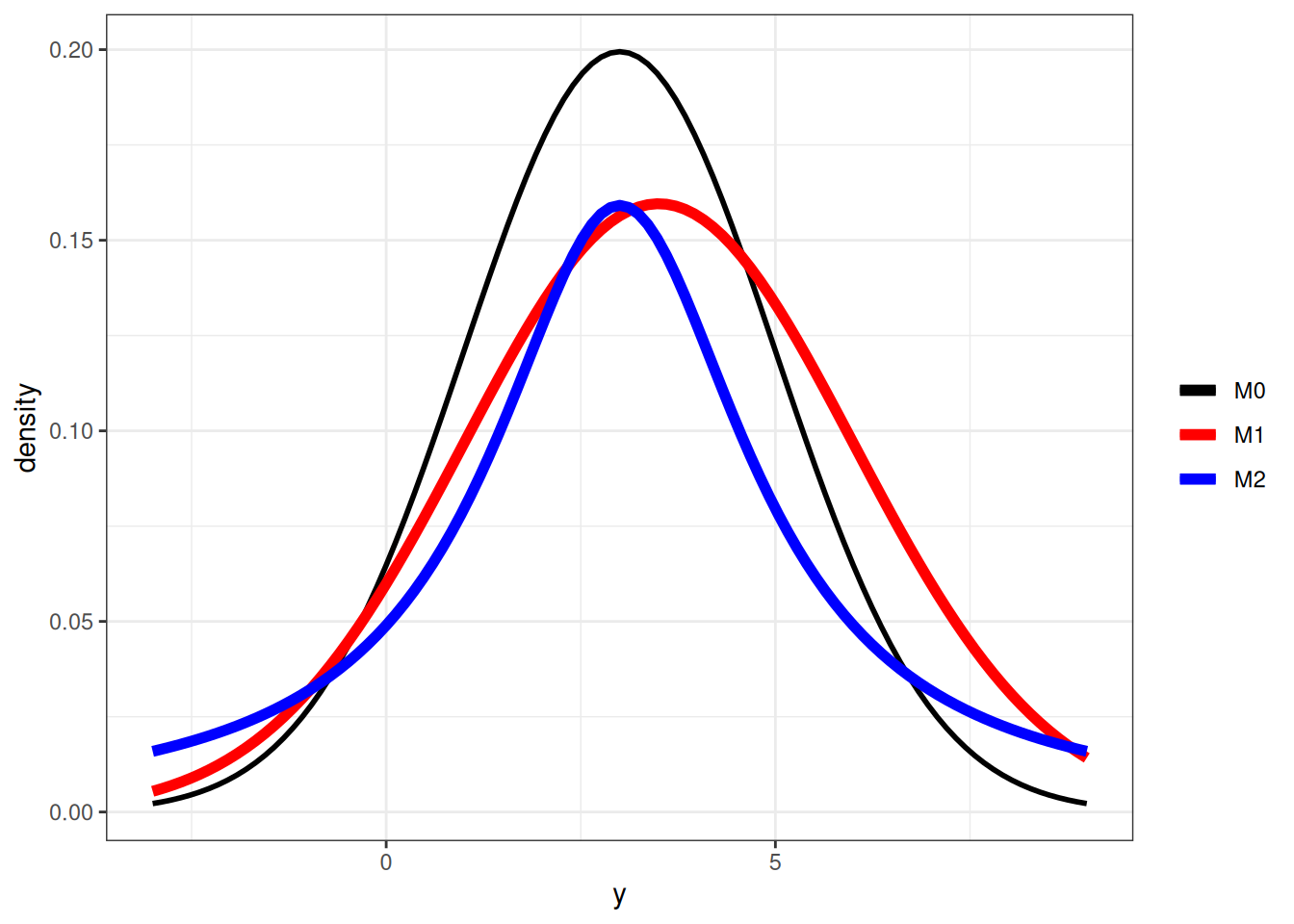
Note that strictly speaking, \(D_\textrm{KL}\) cannot be called a “distance” between two models because in general, \(D_\textrm{KL}(M_0 \mid M_1) \neq D_\textrm{KL}(M_1 \mid M_0)\). As an example, assume that the data are generated by a true model \(M_0\), and we have two candidate models \(M_1\) and \(M_2\), where
One can compute that \(D_\textrm{KL}(M_0 \mid M_1) = 0.0631436\) and \(D_\textrm{KL}(M_0 \mid M_1) = 0.2592445\), and so \(M_1\) is a better model than \(M_2\).
Note that in the expression of \(D_\textrm{KL}\), when talking about the same target model, the first term is always the same and describes the “true” model, \(M_0\). Therefore, it is sufficient to compare models on the second term, \(\int_{-\infty}^\infty p_{M_0} (\boldsymbol{\mathbf{y}}) \log p_{M_1}(\boldsymbol{\mathbf{y}}) \; \mathrm{d}\boldsymbol{\mathbf{y}}\), which can also be written as \(\mathrm{E}=[\log p_{M_1} (\boldsymbol{\mathbf{y}})]\), i.e., the expected log predictive density (elpd). In other words, a model with a larger elpd is preferred over a model with a smaller elpd.
However, we don’t know what \(M_0\) is in real data analysis. If we knew, then we would just need to choose \(M_0\) as our model, and there will be no need for model comparisons. In addition, even if we know that the true model is, e.g., a normal model (which never happens in real data analysis), we still need to estimate the parameter values, and the estimates will not be exactly the same as the true parameter values. However, elpd is defined as the expected value over the true predictive distribution, \(p_{M_0}(y)\), which cannot be obtained without knowing what \(M_0\) is.
So instead, we need to estimate the elpd. A naive way to estimate it is to use the data distribution in place of the true model, but that will lead to an overly optimistic estimate as the sample data are noisy. Computing elpd this way will always favor a more complex model. The ideal way is to collect data on a new, independent sample that share the same data generating process as the current sample, and estimate elpd on the new sample. This is called out-of-sample validation. The problem, of course, is that we usually do not have the resources to collect a new sample.
Therefore, statisticians have worked hard to find ways to estimate elpd from the current sample, and there are two broad approaches:
Information criteria: AIC, DIC, and WAIC, which estimate the elpd in the current sample, minus a correction factor
Cross-validation, which splits the current sample into \(K\) parts, estimates the parameters in \(K - 1\) parts, and estimates the elpd in the remaining part. A special case is when \(K\) = \(N\), each time one uses \(N\) - 1 data points to estimate the model parameters, and estimate the elpd for the observation that was left out. This is called leave-one-out cross-validation (LOO-CV).
11.3 Deviance
Without going too deep into the underlying math, it can be shown that a good estimate of elpd is
\[
\sum_{i = 1}^n \log p_{M_1}(y_i) - p,
\]
where \(p\) is some measure of the number of parameters in \(M_1\). The first term is the likelihood of the model in the current sample. The second term is an adjustment factor so that the quantity above represents the average likelihood of the model in a new sample. It is more common to work with deviance by multiplying the log-likelihood by \(-2\), i.e.,
\[
D = -2 \sum_{i = 1}^n \log p_{M_1}(y_i).
\]
11.3.1 Experiment on Deviance
Now, let’s check the in-sample deviance and out-of-sample deviance of our waffle_divorce data with different polynomial functions. Here is a sample function for computing elpd (with frequentist, just for speed) for polynomials of different degrees:
Code
# Function for computing deviance with different polynomialdeviance_divorce<-function(degree=1,train=10,y=waffle_divorce$Divorce,x=waffle_divorce$Marriage){N<-length(y)# get training sampleif(length(train)==1){train<-sample.int(N, train)}ntrain<-length(train)# Obtain design matrixX<-cbind(1, poly(x, degree, simple =TRUE))# Get elpd for training sampleXtrain<-X[train, ]ytrain<-y[train]betahat<-qr.solve(Xtrain, ytrain)# estimated betasres_train<-ytrain-Xtrain%*%betahatsigmahat<-sqrt(sum(res_train^2)/(ntrain-1-degree))# estimated sigmadeviance_train<--2*sum(dnorm(res_train, sd =sigmahat, log =TRUE))res_test<-y[-train]-X[-train, ]%*%betahatdeviance_test<--2*sum(dnorm(res_test, sd =sigmahat, log =TRUE))data.frame( degree =degree, sample =c("in-sample", "out-of-sample"), deviance =c(deviance_train/ntrain,deviance_test/(N-ntrain)))}
Below shows the in-sample and out-of-sample elpd for the linear model:
deviance_divorce(degree =1, train =train)
And for quadratic:
deviance_divorce(degree =2, train =train)
In general, as you can see, the deviance is smaller for the current data than for the hold-out data. Note that because the training and testing data sets have different sizes, I divided the deviance by the sample size so that they can be compared.
Now let’s run an experiment to check the elpd with different degrees polynomial, with a training sample size of 25:
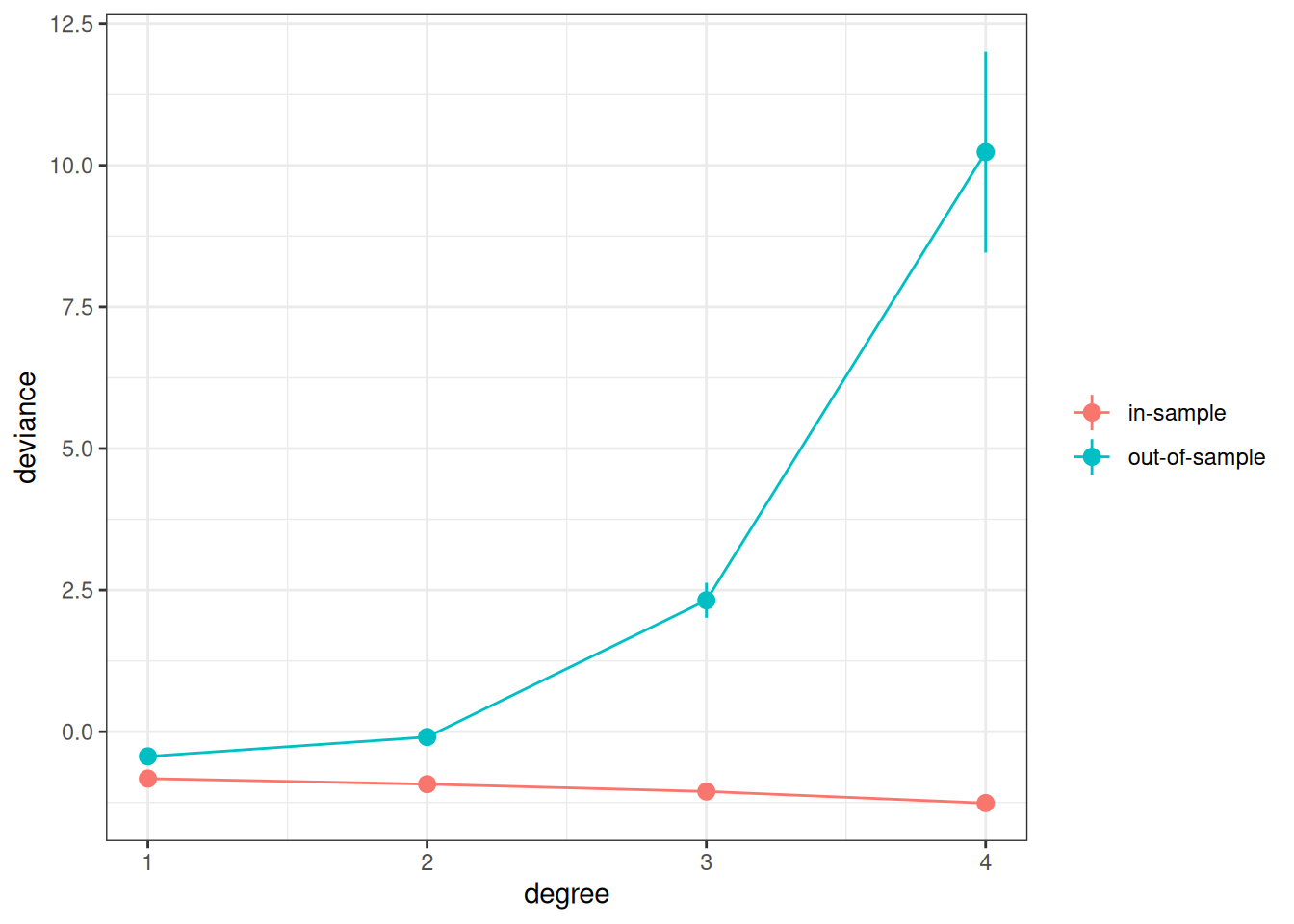
set.seed(1733)# Use the `map` function to run different polynomials, and use the `rerun`# function run the deviance 100 times. The code below runs `deviance_divorce` by# randomly sampling 25 training samples 100 times, and compute the in-sample# and out-of-sample deviance for each.# rerun(100, deviance_divorce(degree = 1, train = 25L)) |># bind_rows()# Now run 1 to 4 degree polynomial, each 1000 times:dev_list<-lapply(1:4, FUN =function(p){results<-replicate(1000, deviance_divorce(degree =p, train =25L), simplify =FALSE)do.call(rbind, results)})dev_df<-do.call(rbind, dev_list)# Plot the resultsdev_df|>ggplot(aes(x =degree, y =deviance, col =sample))+stat_summary()+stat_summary(geom ="line")+labs(col =NULL)
No summary function supplied, defaulting to `mean_se()`
No summary function supplied, defaulting to `mean_se()`
As you can see, the in-sample deviance (red line) keeps decreasing, indicating that a more complex model fits the data better, which is always the case. So if one were to use deviance to determine what model is optimal, one would always choose the most complex model, just like using \(R^2\) (indeed, for linear models, deviance is basically the same as \(R^2\)).
Now, look at the blue line, which represents the deviance computed using the coefficients obtained from the training set but applied to the remaining data. As you can see, the deviance achieves its minimum around the linear and the quadratic model, and starts to increase, meaning that the more complex models do not fit the hold-out data.
A statistical model is used to learn something from a data set that can generalize to other observations. Therefore, we should care about the blue line, instead of the red one. The indices you will see in the remaining of this note are all attempts to approximate the blue line.
More complex models always fit the current data better, but may not generalize to other data. In other words, models that are too complex are not generalizable.
11.4 Information Criteria
We will illustrate the computation of information criteria with Marriage predicting Divorce:
m1<-brm(Divorce~Marriage, data =waffle_divorce, prior =c(prior(student_t(4, 0, 5), class ="Intercept"),prior(normal(0, 2), class ="b"),prior(student_t(4, 0, 1), class ="sigma")), iter =4000, seed =2302, file ="07_m1")
Start sampling
Loading required package: rstan
Loading required package: StanHeaders
rstan version 2.32.5 (Stan version 2.32.2)
For execution on a local, multicore CPU with excess RAM we recommend calling
options(mc.cores = parallel::detectCores()).
To avoid recompilation of unchanged Stan programs, we recommend calling
rstan_options(auto_write = TRUE)
For within-chain threading using `reduce_sum()` or `map_rect()` Stan functions,
change `threads_per_chain` option:
rstan_options(threads_per_chain = 1)
Attaching package: 'rstan'
The following objects are masked from 'package:posterior':
ess_bulk, ess_tail
The following object is masked from 'package:tidyr':
extract
11.4.1 Akaike Information Criteria (AIC)
Multiplying the quantity of elpd - \(p\) by \(-2\), or deviance + 2\(p\), with the deviance obtained using the maximum likelihood estimates (MLEs) for the parameters, gives you the formula for AIC:
\[
\textrm{AIC} = D(\hat \theta) + 2p,
\]
and \(p\) in AIC is just the number of parameters. As we have multiplied by a negative number, maximizing the estimate of elpd is equivalent to minimizing the AIC, so one would prefer a model with the smallest AIC.
The AIC is not Bayesian because it only uses point estimates (MLEs) of parameters rather than their posterior distributions. Also, it does not take into account any prior information.
# Frequentist modelm1_freq<-lm(m1$formula, data =m1$data)AIC(m1_freq)
[1] -30.96869
11.4.2 Deviance Information Criteria (DIC)
The definition of AIC assumes that the parameter estimates are known or are maximum likelihood estimates. The DIC, instead, replaces those with the posterior distribution of the parameters. The general formula for DIC is
where \(p_D\) is the effective number of parameters estimated in the Markov chain. Although DIC does take into account the prior distributions, it does not consider the full posterior distributions of the parameters.
11.4.3 Watanabe-Akaike Information Criteria (WAIC)
A further modification is to use the log pointwise posterior predictive density, with the effective number of parameters computed using the posterior variance of the likelihood.
where \(\mathrm{E}[p(y_i \mid \boldsymbol{\mathbf{\theta}}, \boldsymbol{\mathbf{y}})]\) is the posterior mean of the likelihood of the \(i\)th observation. The WAIC incorporates prior information, and the use of pointwise likelihood makes it more robust when the posterior distributions deviate from normality. In general, WAIC is a better estimate of the out-of-sample deviance than AIC and DIC.
waic(m1)# built-in function in brms
Warning:
1 (2.0%) p_waic estimates greater than 0.4. We recommend trying loo instead.
Computed from 8000 by 50 log-likelihood matrix.
Estimate SE
elpd_waic 15.2 4.9
p_waic 3.2 0.9
waic -30.3 9.9
1 (2.0%) p_waic estimates greater than 0.4. We recommend trying loo instead.
11.4.4 Leave-One-Out Cross-Validation
The idea of cross-validation is to split the sample so that it imitates the scenario of estimating the parameters in part of the data and predicting the remaining part. The part used for estimation is called the training set, and the part used for prediction is called the validation set. Leave-one-out information criteria (LOO-IC) means that one uses \(N - 1\) observations as the training set and 1 observation as the validation sample and repeat the process \(N\) times so that a different observation is being predicted each time. Adding up the prediction results will give an estimate of elpd that closely approximates the results that would be obtained by collecting new data and doing the validation. To make it more concrete, we can go back to the waffle_divorce data with Marriage predicting Divorce. We can do this for case #1 (Alabama), as an example:
# Estimate the model without case #1m1_no1<-update(m1, newdata =waffle_divorce[-1, ])
# The log predictive density for case #1mean(log_lik(m1_no1, newdata =waffle_divorce[1, ]))
[1] -0.8111212
Because LOO-IC requires fitting the model \(N\) times, it is generally very computationally intensive. There are, however, shortcuts for some models to make the computation faster. WAIC can also be treated as a fast approximation of LOO-IC, although LOO-IC is more robust and will be a better estimate of out-of-sample deviance. The loo package uses the so-called Pareto smoothed importance sampling (PSIS) to approximate LOO-IC without repeating the process \(N\) times.
Here is the LOO-IC for the model:
loo(m1)
Computed from 8000 by 50 log-likelihood matrix.
Estimate SE
elpd_loo 15.1 5.0
p_loo 3.3 1.0
looic -30.2 9.9
------
MCSE of elpd_loo is 0.0.
MCSE and ESS estimates assume MCMC draws (r_eff in [0.7, 1.0]).
All Pareto k estimates are good (k < 0.7).
See help('pareto-k-diagnostic') for details.
You can save the WAIC and the LOO-IC information to the fitted result:
# Note, m1 has been fit before; the `update()` function# can be used to simply change the formula, and brms will# determine whether it needs re-compiling.# M2: Add South and interactionm2<-update(m1, formula =Divorce~Marriage*South, newdata =waffle_divorce)m2<-add_criterion(m2, c("loo", "waic"))
Warning:
1 (2.0%) p_waic estimates greater than 0.4. We recommend trying loo instead.
# M3: Spline function for Marriagem3<-update(m1, formula =Divorce~South+s(Marriage, by =South), newdata =waffle_divorce, control =list(adapt_delta =.999))m3<-add_criterion(m3, c("loo", "waic"))
Warning: Found 2 observations with a pareto_k > 0.7 in model 'm3'. We recommend
to set 'moment_match = TRUE' in order to perform moment matching for
problematic observations.
Warning:
4 (8.0%) p_waic estimates greater than 0.4. We recommend trying loo instead.
# M4: Three-way interactionsm4<-update(m1, formula =Divorce~Marriage*MedianAgeMarriage*South, newdata =waffle_divorce, control =list(max_treedepth =12))# increase due to warningm4<-add_criterion(m4, c("loo", "waic"))
Warning: Found 1 observations with a pareto_k > 0.7 in model 'm4'. We recommend
to set 'moment_match = TRUE' in order to perform moment matching for
problematic observations.
Warning:
3 (6.0%) p_waic estimates greater than 0.4. We recommend trying loo instead.
The first model only has Marriage as a predictor, which means that the coefficients for South and MedianAgeMarriage are assumed to be zero. The second model added South and its interaction with Marriage as a predictor. The third model includes a smoothing spline term (a flexible non-linear function, within the class of linear models), whereas the fourth model also includes MedianAgeMarriage and all two-way and three-way interactions. Now, we can compare the four models:
Warning:
`modelsummary` uses the `performance` package to extract goodness-of-fit
statistics from models of this class. You can specify the statistics you wish
to compute by supplying a `metrics` argument to `modelsummary`, which will then
push it forward to `performance`. Acceptable values are: "all", "common",
"none", or a character vector of metrics names. For example: `modelsummary(mod,
metrics = c("RMSE", "R2")` Note that some metrics are computationally
expensive. See `?performance::performance` for details.
This warning appears once per session.
M1
M2
M3
M4
b_Intercept
0.61 [0.35, 0.87]
0.67 [0.41, 0.92]
0.94 [0.89, 0.99]
5.50 [1.86, 9.13]
b_Marriage
0.18 [0.05, 0.31]
0.13 [0.01, 0.26]
−1.20 [−2.88, 0.50]
sigma
0.17 [0.14, 0.21]
0.16 [0.13, 0.20]
0.15 [0.12, 0.19]
0.14 [0.11, 0.18]
b_Southsouth
−0.62 [−1.44, 0.19]
0.10 [−0.03, 0.22]
0.34 [−3.00, 3.88]
b_Marriage × Southsouth
0.36 [−0.03, 0.76]
0.49 [−1.62, 2.81]
bs_sMarriage × SouthnonMsouth_1
−0.46 [−3.34, 1.51]
bs_sMarriage × Southsouth_1
1.27 [−2.02, 3.54]
sds_sMarriageSouthnonMsouth_1
0.87 [0.05, 2.60]
sds_sMarriageSouthsouth_1
0.48 [0.02, 2.48]
b_MedianAgeMarriage
−1.72 [−3.10, −0.32]
b_Marriage × MedianAgeMarriage
0.45 [−0.22, 1.10]
b_MedianAgeMarriage × Southsouth
−0.37 [−1.72, 0.96]
b_Marriage × MedianAgeMarriage × Southsouth
−0.07 [−1.08, 0.88]
Num.Obs.
50
50
50
50
R2
0.139
0.305
0.388
0.490
R2 Adj.
0.072
0.209
0.164
0.367
ELPD
15.1
18.3
17.5
23.7
ELPD s.e.
5.0
5.5
5.9
6.1
LOOIC
−30.2
−36.7
−35.1
−47.3
LOOIC s.e.
9.9
11.0
11.9
12.3
WAIC
−30.3
−36.8
−36.7
−48.1
RMSE
0.17
0.15
0.14
0.13
Model 4 has the lowest LOO-IC, so one may conclude that Model 4 is the best model among the four, for prediction purposes.
Vehtari, A., Gelman, A., & Gabry, J. (2017). Practical Bayesian model evaluation using leave-one-out cross-validation and WAIC. Statistics and Computing, 27(5), 1413–1432. https://doi.org/10.1007/s11222-016-9696-4
Source Code
# Model Comparison\newcommand{\E}{\mathrm{E}}\newcommand{\bv}[1]{\boldsymbol{\mathbf{#1}}}\newcommand{\SD}{\mathit{SD}}\newcommand{\DKL}{D_\textrm{KL}}\newcommand{\dd}{\; \mathrm{d}}```{r}#| include: falsecomma <-function(x, digits =2L) format(x, digits = digits, big.mark =",")library(tidyverse)theme_set(theme_bw() +theme(panel.grid.major.y =element_line(color ="grey92")))library(gridExtra)library(posterior)library(brms)options(brms.backend ="cmdstanr")library(modelsummary)```## Overfitting and UnderfittingIn statistical modeling, a more complex model almost always results in a better fit to the data. Roughly speaking, a more complex model means a model with more parameters. However, as you will see later, determining the number of parameters in Bayesian analyses is not straightforward. On the extreme side, if one has 10 observations, a model with 10 parameters will perfectly predict every single data point (by just having a parameter to predict each data point). However, there are two problems with too complex a model. First, an increasingly complex model makes it increasingly hard to extract useful information from the data. Instead of describing the relationship between two variables, like `Marriage` and `Divorce`, by a straight line, one ends up with a crazy model that is difficult to make sense of. Second, as you will also see, the more complex a model, the more is the risk that it *overfits* the current data, such that it does not work for future observations.For example, let's randomly sample 10 states in the `waffle_divorce` data set and build some models.```{r}waffle_divorce <-read_delim( # read delimited files"data/WaffleDivorce.csv",delim =";")# Rescale Marriage and Divorce by dividing by 10waffle_divorce$Marriage <- waffle_divorce$Marriage /10waffle_divorce$Divorce <- waffle_divorce$Divorce /10waffle_divorce$MedianAgeMarriage <- waffle_divorce$MedianAgeMarriage /10# Recode `South` to a factor variablewaffle_divorce$South <-factor(waffle_divorce$South,levels =c(0, 1),labels =c("non-south", "south"))``````{r}set.seed(1547) # set the seed for reproducibility# Sample 10 observationstrain <-sample.int(nrow(waffle_divorce), 10L)wd_sub <- waffle_divorce[train, ]base <-ggplot(aes(x = Marriage, y = Divorce),data = wd_sub) +geom_point() +coord_cartesian(ylim =c(0.6, 1.4)) +xlim(range(waffle_divorce$Marriage))ggplot(waffle_divorce,aes(x = Marriage, y = Divorce)) +geom_point(col ="lightblue") +geom_point(size =1.5, data = wd_sub, col ="red") +coord_cartesian(ylim =c(0.6, 1.4)) +xlim(range(waffle_divorce$Marriage))```When using `Marriage` to predict `Divorce`, we can use beyond a linear regression line by using higher-order *polynomials*. For example, a second-order polynomial represents a quadratic effect (with one turning point); it goes to cubic, quartic, and more. The figure below shows the fit from a linear effect of `Marriage`, a quadratic effect, and increasingly complex models up to a sixth-degree polynomial. As you can see, as the model gets more complex, the fitted line tries to capture all the 10 points really well, with an increasing $R^2$. However, the standard error around the fitted line also gets larger and bizarre, meaning more uncertainty in the model parameters.```{r}#| label: fig-overfit#| code-fold: true#| fig-cap: "Fit of models on the 10 random cases. Top panel: linear, quadratic, and cubic; bottom panel: 4th, 5th, and 6th degree polynomials"r2 <-function(object, newresp, newdata) {# Function for computing R^2 ypred <-predict(object, newdata = newdata)cor(ypred, newresp)^2}rmse <-function(object, newresp, newdata) {# Function for RMSE ypred <-predict(object, newdata = newdata)sqrt(mean((ypred - newresp)^2))}# Create six plots through a loopp_list <-map(1:6, function(i) {# Use frequentist analyses for speed mod <-lm(Divorce ~poly(Marriage, degree = i), data = wd_sub) base +geom_smooth(method ="lm", formula = y ~poly(x, i), level = .80,fullrange =TRUE) +annotate("text", x =1.7, y =1.4,label =paste0("italic(R)^2 == ",round(r2(mod, wd_sub$Divorce), 2)),parse =TRUE) +annotate("text", x =1.7, y =1.2,label =paste0("RMSE == ",round(rmse(mod, wd_sub$Divorce), 2)),parse =TRUE)})do.call(grid.arrange, c(p_list, nrow =2))```Another way to look at model accuracy is the *Root Mean Squared Error* (RMSE), defined as the square root of the average squared prediction error. RMSE is a measure of prediction error. The smaller the RMSE, the better the prediction is. As you can see in the above figure, more complex models always reduce the RMSE in the data we use to fit the model (also called training data).However, if I take the estimated regression line/curve based on the subsample of 10 observations, and predict the remaining cases in the data set, things will be different. As you can see in the figure below, whereas prediction error is comparable for the linear and the quadratic model, polynomials of higher degrees predict the data really badly. When you use a complex model in a data set, it tailors the coefficients to any sampling errors and noise in the data such that it will not generalize to new observations. Therefore, our goal in model comparison is to choose a model complex enough to capture the essence of the data generation process (and thus avoid *underfitting*), but not too complex such that it suffers from *overfitting*.```{r}#| label: fig-overfit-generalize#| code-fold: true#| fig-cap: "Using the regression lines based on 10 random cases to predict the remaining 40 cases. Top panel: linear, quadratic, and cubic; bottom panel: 4th, 5th, and 6th degree polynomials"base2 <-ggplot(aes(x = Marriage, y = Divorce),data = waffle_divorce[-train, ]) +geom_point() +coord_cartesian(ylim =c(0.6, 1.4)) +xlim(range(waffle_divorce$Marriage))# Create six plots through a loopp_list2 <-map(1:6, function(i) {# Use frequentist analyses for speed mod <-lm(Divorce ~poly(Marriage, degree = i), data = wd_sub)# New data and response test_dat <- waffle_divorce[-train, ] ynew <- test_dat$Divorce base2 +geom_smooth(data = wd_sub, method ="lm", formula = y ~poly(x, i),level = .80, fullrange =TRUE) +annotate("text", x =1.7, y =1.4,label =paste0("italic(R)^2 == ",round(r2(mod, ynew, test_dat), 2)),parse =TRUE) +annotate("text", x =1.7, y =1.2,label =paste0("RMSE == ",round(rmse(mod, ynew, test_dat), 2)),parse =TRUE)})do.call(grid.arrange, c(p_list2, nrow =2))```The goal of statistical modeling is to choose an optimal model between the overfitting/underfitting dichotomy. In machine learning, this is also commonly referred to as the bias-variance trade-off, as a model that is too simple tends to produce biased predictions because it does not capture the essence of the data generating process. In contrast, a overly complex model is unbiased but results in a lot of uncertainty in the prediction because there are too many unnecessary components that can affect predictions, as indicated in the confidence bands around the 6th-degree polynomial line.Polynomials of varying degrees are merely one example of comparing simple to complex models. You can think about:- models with and without interactions, - models with a few predictors versus hundreds of predictors, - regression analyses versus multilevel models, etc. Whereas one can always avoid underfitting by fitting a more and more complex model, we need tools to keep us from overfitting. This lecture is about finding an optimal model that avoids overfitting and avoids underfitting. You will learn to perform model comparisons with information criteria to find a model that has a better balance between overfitting and underfitting. ## Kullback-Leibler DivergenceWhen comparing models (e.g., linear vs. quadratic), we prefer models closer to the "true" data-generating process. To do so, we need some ways to quantify the degree of "closeness" to the true model. In this context, models comprise both the distributional family *and* the parameter values. For example, the model $y_i \sim N(5, 2)$ is a different model than $y_i \sim N(3, 2)$, which is a different model than $y_i \sim \mathrm{Gamma}(2, 2)$. The first two have the same family but different parameter values (different means, same $\SD$). In contrast, the last two have different distributional families (Normal vs. Gamma).To measure the degree of "closeness" between two models, $M_0$ and $M_1$, by far the most popular metric in statistics is the *Kullback-Liebler Divergence* (or Kullback-Liebler discrepancy; $\DKL$). By definition,$$\begin{aligned}\DKL(M_0 \mid M_1) & = \int_{-\infty}^\infty p_{M_0} (\bv y) \log \frac{p_{M_0}(\bv y)}{p_{M_1}(\bv y)} \dd \bv y \\ & = \int_{-\infty}^\infty p_{M_0} (\bv y) \log p_{M_0}(\bv y) \dd \bv y - \int_{-\infty}^\infty p_{M_0} (\bv y) \log p_{M_1}(\bv y) \dd \bv y. \end{aligned}$$Note that strictly speaking, $\DKL$ cannot be called a "distance" between two models because in general, $\DKL(M_0 \mid M_1) \neq \DKL(M_1 \mid M_0)$. As an example, assume that the data are generated by a true model $M_0$, and we have two candidate models $M_1$ and $M_2$, where- $M_0: y \sim N(3, 2)$- $M_1: y \sim N(3.5, 2.5)$- $M_2: y \sim \mathrm{Cauchy}(3, 2)$```{r}#| label: fig-divergence#| code-fold: true#| fig-cap: Density for $M_0$, $M_1$, and $M_2$ggplot(data.frame(x =c(-3, 9)), aes(x = x)) +stat_function(fun = dnorm, args =list(mean =3, sd =2),aes(col ="M0"), linewidth =1) +stat_function(fun = dnorm, args =list(mean =3.5, sd =2.5),aes(col ="M1"), linewidth =2) +stat_function(fun = dcauchy, args =list(location =3, scale =2),aes(col ="M2"), linewidth =2) +scale_color_manual(values =c("black", "red", "blue"),labels =c("M0", "M1", "M2")) +labs(x ="y", y ="density", col =NULL)``````{r}f1 <-function(x) {dnorm(x, 3, 2) * (dnorm(x, 3, 2, log =TRUE) -dnorm(x, 3.5, 2.5, log =TRUE))}f2 <-function(x) {dnorm(x, 3, 2) * (dnorm(x, 3, 2, log =TRUE) -dcauchy(x, 3, 2, log =TRUE))}```One can compute that $\DKL(M_0 \mid M_1) = `r integrate(f1, -Inf, Inf)$value`$ and $\DKL(M_0 \mid M_1) = `r integrate(f2, -Inf, Inf)$value`$, and so $M_1$ is a better model than $M_2$. Note that in the expression of $\DKL$, when talking about the same target model, the first term is always the same and describes the "true" model, $M_0$. Therefore, it is sufficient to compare models on the second term, $\int_{-\infty}^\infty p_{M_0} (\bv y) \log p_{M_1}(\bv y) \dd \bv y$, which can also be written as $\E=[\log p_{M_1} (\bv y)]$, i.e., the *expected log predictive density* (*elpd*). In other words, a model with a larger elpd is preferred over a model with a smaller elpd.However, we don't know what $M_0$ is in real data analysis. If we knew, then we would just need to choose $M_0$ as our model, and there will be no need for model comparisons. In addition, even if we know that the true model is, e.g., a normal model (which never happens in real data analysis), we still need to estimate the parameter values, and the estimates will not be exactly the same as the true parameter values. However, elpd is defined as the expected value over the true predictive distribution, $p_{M_0}(y)$, which cannot be obtained without knowing what $M_0$ is.So instead, we need to estimate the elpd. A naive way to estimate it is to use the data distribution in place of the true model, but that will lead to an overly optimistic estimate as the sample data are noisy. Computing elpd this way will always favor a more complex model. The ideal way is to collect data on a new, independent sample that share the same data generating process as the current sample, and estimate elpd on the new sample. This is called *out-of-sample validation*. The problem, of course, is that we usually do not have the resources to collect a new sample.Therefore, statisticians have worked hard to find ways to estimate elpd from the current sample, and there are two broad approaches:- Information criteria: AIC, DIC, and WAIC, which estimate the elpd in the current sample, minus a correction factor- Cross-validation, which splits the current sample into $K$ parts, estimates the parameters in $K - 1$ parts, and estimates the elpd in the remaining part. A special case is when $K$ = $N$, each time one uses $N$ - 1 data points to estimate the model parameters, and estimate the elpd for the observation that was left out. This is called *leave-one-out* cross-validation (LOO-CV).## DevianceWithout going too deep into the underlying math, it can be shown that a good estimate of elpd is $$\sum_{i = 1}^n \log p_{M_1}(y_i) - p,$$where $p$ is some measure of the number of parameters in $M_1$. The first term is the likelihood of the model in the current sample. The second term is an adjustment factor so that the quantity above represents the average likelihood of the model *in a new sample*. It is more common to work with *deviance* by multiplying the log-likelihood by $-2$, i.e.,$$D = -2 \sum_{i = 1}^n \log p_{M_1}(y_i).$$### Experiment on DevianceNow, let's check the in-sample deviance and out-of-sample deviance of our `waffle_divorce` data with different polynomial functions. Here is a sample function for computing elpd (with frequentist, just for speed) for polynomials of different degrees:```{r}#| code-fold: true# Function for computing deviance with different polynomialdeviance_divorce <-function(degree =1,train =10,y = waffle_divorce$Divorce,x = waffle_divorce$Marriage) { N <-length(y)# get training sampleif (length(train) ==1) { train <-sample.int(N, train) } ntrain <-length(train)# Obtain design matrix X <-cbind(1, poly(x, degree, simple =TRUE))# Get elpd for training sample Xtrain <- X[train, ] ytrain <- y[train] betahat <-qr.solve(Xtrain, ytrain) # estimated betas res_train <- ytrain - Xtrain %*% betahat sigmahat <-sqrt(sum(res_train^2) / (ntrain -1- degree)) # estimated sigma deviance_train <--2*sum(dnorm(res_train, sd = sigmahat, log =TRUE)) res_test <- y[-train] - X[-train, ] %*% betahat deviance_test <--2*sum(dnorm(res_test, sd = sigmahat, log =TRUE))data.frame(degree = degree,sample =c("in-sample", "out-of-sample"),deviance =c(deviance_train / ntrain, deviance_test / (N - ntrain)) )}```Below shows the in-sample and out-of-sample elpd for the linear model:```{r dev1}deviance_divorce(degree = 1, train = train)```And for quadratic:```{r dev2}deviance_divorce(degree = 2, train = train)```In general, as you can see, the deviance is smaller for the current data than for the hold-out data. Note that because the training and testing data sets have different sizes, I divided the deviance by the sample size so that they can be compared. Now let's run an experiment to check the elpd with different degrees polynomial, with a training sample size of 25:```{r dev_df-plot}set.seed(1733)# Use the `map` function to run different polynomials, and use the `rerun`# function run the deviance 100 times. The code below runs `deviance_divorce` by# randomly sampling 25 training samples 100 times, and compute the in-sample# and out-of-sample deviance for each.# rerun(100, deviance_divorce(degree = 1, train = 25L)) |># bind_rows()# Now run 1 to 4 degree polynomial, each 1000 times:dev_list <- lapply(1:4, FUN = function(p) { results <- replicate(1000, deviance_divorce(degree = p, train = 25L), simplify = FALSE) do.call(rbind, results)})dev_df <- do.call(rbind, dev_list)# Plot the resultsdev_df |> ggplot(aes(x = degree, y = deviance, col = sample)) + stat_summary() + stat_summary(geom = "line") + labs(col = NULL)```As you can see, the in-sample deviance (red line) keeps decreasing, indicating that a more complex model fits the data better, which is always the case. So if one were to use deviance to determine what model is optimal, one would always choose the most complex model, just like using $R^2$ (indeed, for linear models, deviance is basically the same as $R^2$).Now, look at the blue line, which represents the deviance computed using the coefficients obtained from the training set but applied to the remaining data. As you can see, the deviance achieves its minimum around the linear and the quadratic model, and starts to increase, meaning that the more complex models do not fit the hold-out data. A statistical model is used to learn something from a data set that can generalize to other observations. Therefore, we should care about the blue line, instead of the red one. The indices you will see in the remaining of this note are all attempts to approximate the blue line. > More complex models always fit the current data better, but may not generalize to other data. In other words, models that are too complex are not generalizable.## Information CriteriaWe will illustrate the computation of information criteria with `Marriage` predicting `Divorce`:```{r}#| results: hidem1 <-brm(Divorce ~ Marriage, data = waffle_divorce,prior =c(prior(student_t(4, 0, 5), class ="Intercept"),prior(normal(0, 2), class ="b"),prior(student_t(4, 0, 1), class ="sigma")),iter =4000,seed =2302,file ="07_m1")```### Akaike Information Criteria (AIC)Multiplying the quantity of elpd - $p$ by $-2$, or deviance + 2$p$, with the deviance obtained using the maximum likelihood estimates (MLEs) for the parameters, gives you the formula for AIC:$$\textrm{AIC} = D(\hat \theta) + 2p,$$and $p$ in AIC is just the number of parameters. As we have multiplied by a negative number, maximizing the estimate of elpd is equivalent to minimizing the AIC, so one would prefer a model with the smallest AIC.The AIC is not Bayesian because it only uses point estimates (MLEs) of parameters rather than their posterior distributions. Also, it does not take into account any prior information.```{r}# Frequentist modelm1_freq <-lm(m1$formula, data = m1$data)AIC(m1_freq)```### Deviance Information Criteria (DIC)The definition of AIC assumes that the parameter estimates are known or are maximum likelihood estimates. The DIC, instead, replaces those with the posterior distribution of the parameters. The general formula for DIC is$$\textrm{DIC} = \E(D \mid \bv y) + 2 p_D,$$where $p_D$ is the effective number of parameters estimated in the Markov chain. Although DIC does take into account the prior distributions, it does not consider the full posterior distributions of the parameters.```{r}# Function to compute DICdic_brmsfit <-function(object) { Dbar <--2*mean(rowSums(log_lik(object))) res <-residuals(object)[ , "Estimate"] sigma <-posterior_summary(object, variable ="sigma")[ , "Estimate"] Dhat <--2*sum(dnorm(res, sd = sigma, log =TRUE)) p <- Dbar - Dhat elpd <- Dhat /-2- pdata.frame(elpd_dic = elpd, p_dic = p, dic = Dhat +2* p,row.names ="Estimate")}dic_brmsfit(m1)```### Watanabe-Akaike Information Criteria (WAIC)A further modification is to use the *log pointwise posterior predictive density*, with the effective number of parameters computed using the posterior variance of the likelihood. $$\textrm{WAIC} = -2 \sum_{i = 1}^n \log \E[p(y_i \mid \bv \theta, \bv y)] + 2 p_\textrm{WAIC},$$where $\E[p(y_i \mid \bv \theta, \bv y)]$ is the posterior mean of the likelihood of the $i$th observation. The WAIC incorporates prior information, and the use of pointwise likelihood makes it more robust when the posterior distributions deviate from normality. In general, WAIC is a better estimate of the out-of-sample deviance than AIC and DIC.```{r}waic(m1) # built-in function in brms```### Leave-One-Out Cross-ValidationThe idea of cross-validation is to split the sample so that it imitates the scenario of estimating the parameters in part of the data and predicting the remaining part. The part used for estimation is called the *training set*, and the part used for prediction is called the *validation set*. Leave-one-out information criteria (LOO-IC) means that one uses $N - 1$ observations as the training set and 1 observation as the validation sample and repeat the process $N$ times so that a different observation is being predicted each time. Adding up the prediction results will give an estimate of elpd that closely approximates the results that would be obtained by collecting new data and doing the validation. To make it more concrete, we can go back to the `waffle_divorce` data with `Marriage` predicting `Divorce`. We can do this for case #1 (Alabama), as an example:```{r}#| results: hide#| message: false# Estimate the model without case #1m1_no1 <-update(m1, newdata = waffle_divorce[-1, ])``````{r loglik_1}# The log predictive density for case #1mean(log_lik(m1_no1, newdata = waffle_divorce[1, ]))```Because LOO-IC requires fitting the model $N$ times, it is generally very computationally intensive. There are, however, shortcuts for some models to make the computation faster. WAIC can also be treated as a fast approximation of LOO-IC, although LOO-IC is more robust and will be a better estimate of out-of-sample deviance. The `loo` package uses the so-called Pareto smoothed importance sampling (PSIS) to approximate LOO-IC without repeating the process $N$ times.Here is the LOO-IC for the model:```{r}loo(m1)```You can save the WAIC and the LOO-IC information to the fitted result:```{r}m1 <-add_criterion(m1, criterion =c("loo", "waic"))```See @vehtari2017 for more discussions on WAIC and LOO-IC. ***### ExampleConsider four potential models in predicting `Divorce`:$$\texttt{Divorce}_i \sim N(\mu_i, \sigma)$$- M1: `Marriage`- M2: `Marriage`, `South`, `Marriage` $\times$ `South`- M3: `South`, smoothing spline of `Marriage` by `South`- M4: `Marriage`, `South`, `MedianAgeMarriage`, `Marriage` $\times$ `South`, `Marriage` $\times$ `MedianAgeMarriage`, `South` $\times$ `MedianAgeMarriage`, `Marriage` $\times$ `South` $\times$ `MedianAgeMarriage````{r}#| results: hide#| message: false# Note, m1 has been fit before; the `update()` function# can be used to simply change the formula, and brms will# determine whether it needs re-compiling.# M2: Add South and interactionm2 <-update(m1, formula = Divorce ~ Marriage * South,newdata = waffle_divorce)m2 <-add_criterion(m2, c("loo", "waic"))# M3: Spline function for Marriagem3 <-update(m1, formula = Divorce ~ South +s(Marriage, by = South),newdata = waffle_divorce,control =list(adapt_delta = .999))m3 <-add_criterion(m3, c("loo", "waic"))# M4: Three-way interactionsm4 <-update(m1, formula = Divorce ~ Marriage * MedianAgeMarriage * South,newdata = waffle_divorce,control =list(max_treedepth =12)) # increase due to warningm4 <-add_criterion(m4, c("loo", "waic"))```The first model only has `Marriage` as a predictor, which means that the coefficients for `South` and `MedianAgeMarriage` are assumed to be zero. The second model added `South` and its interaction with `Marriage` as a predictor. The third model includes a smoothing spline term (a flexible non-linear function, within the class of linear models), whereas the fourth model also includes `MedianAgeMarriage` and all two-way and three-way interactions. Now, we can compare the four models:```{r}loo_compare(m1, m2, m3, m4)# m4 is the best``````{r}msummary(list(M1 = m1, M2 = m2, M3 = m3, M4 = m4),estimate ="{estimate} [{conf.low}, {conf.high}]",statistic =NULL, fmt =2)```Model 4 has the lowest LOO-IC, so one may conclude that Model 4 is the best model among the four, **for prediction purposes**.***